Last updated on 6월 19th, 2025 at 03:42 오후
구글 스태프가 알려주는 AI의 미래:
에이전트형 LLM 기술 완전 정복

🧠 AI 에이전트란?
저희 팀은 Google에서 에이전트형 워크플로(agentic workflows) 를 집중적으로 연구하고 있어요. 그런데 “AI 에이전트”라는 말은 요즘 정말 다양한 의미로 쓰이고 있어서, 사람마다 조금씩 다르게 해석하곤 해요. 어떤 사람은 “LLM에게 한 번 요청(request)을 보내는 것도 에이전트다.”
라고 말하기도 하고, 어떤 사람은 “서로 다른 LLM 여러 개가 협업하는 시스템이 진짜 에이전트다.” 라고 정의하기도 하죠.
그 외에도,
- LLM이 복잡한 작업을 여러 하위 작업(subtasks) 으로 나누거나,
- 외부 도구를 호출(call tools) 해서 문제를 해결할 수 있을 때,
그걸 에이전트적 행동(agentic behavior) 이라고 부르기도 합니다.
🔍 에이전트의 핵심: 계획과 도구 사용
제가 생각하는 에이전트형 시스템의 핵심 요소는 두 가지예요:
- 계획(Planning)과 추론(Reasoning)
- 도구 사용(Tool Use)
이 두 가지를 바탕으로, 이제부터는 대표적인 연구 사례 두 가지를 소개할게요:
- ReAct (Reasoning + Acting)
- Toolformer (Meta에서 개발한 도구 사용 학습법)

🧩 첫 번째: ReAct 사고와 행동의 결합
ReAct 논문은 에이전트 워크플로의 대표 사례 중 하나예요. 이 논문은 두 가지 기존 접근을 하나로 결합한 것이에요:
- Reasoning trace only (생각만 하고 끝내는 방식)
- Action trace only (행동만 하고 생각은 없는 방식)
ReAct는 이 둘을 하나로 합쳐서 생각과 행동을 오가며 문제를 해결하는 하이브리드 모델을 만든 거예요.
🍿 예시: 영화 정보 검증
이 예시는 간단한 영화 퀴즈처럼 보이지만, 구조는 꽤 흥미롭습니다.
문제:
“<Rain Over Me>는 2010년에 제작된 미국 영화다.”
이게 맞는 말인지 판단해보세요.
- ReAct는 먼저 “이게 맞는 말인지 찾아봐야겠다” 라고 생각(trace)합니다.
- 그 다음, 웹 검색(action) 을 실행합니다.
검색 결과는 이렇게 나옵니다:
“<Rain Over Me>는 2007년에 개봉했다.” - 그리고 나서, 최종적으로 “틀린 정보입니다(refute)” 라고 판단합니다.
즉, 모델은
- 생각 → 행동 → 관찰 → 판단
이라는 일련의 흐름을 따르는 거죠.
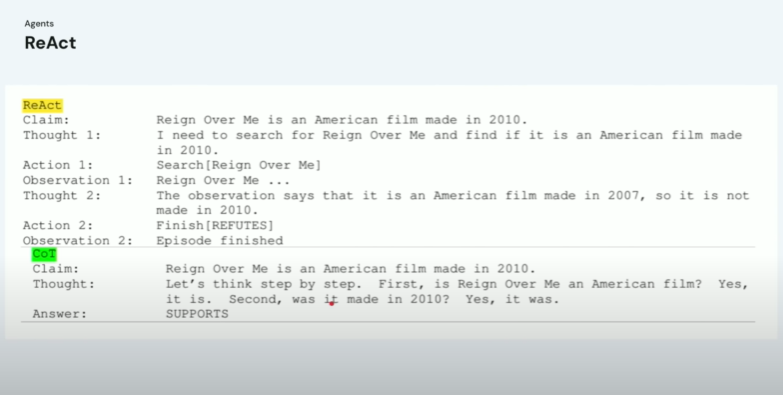
🧱 비교: Chain of Thought와의 차이
기존의 체인 오브 쏘트(CoT) 방식은 단순히 “단계적으로 생각해보자.” 고 유도하는 방식이었어요. 하지만 CoT는 외부 정보 접근 없이 모델이 아는 것만으로 생각하기 때문에, 틀린 정보를 사실처럼 말하는 경우도 있었죠. 반면 ReAct는 사고 과정도 포함되고, 행동(도구 호출) 도 포함되기 때문에, 더 정확하고 유연한 문제 해결이 가능해요.
🥄 예시: 후추통을 서랍 위에 놓는 게임
다소 엉뚱하지만 직관적인 또 다른 예시가 있어요 😄 ReAct 논문에서는 마치 ‘던전 게임’ 같은 환경에서, “후추통을 서랍 위에 놓아라.” 라는 지시를 수행하는 실험도 진행했어요. Action-only 모델은 후추통이 없는 곳에서 계속 줍기만 시도하다가 루프에 빠졌고, ReAct는 “후추통이 없네? 그럼 다른 방으로 이동해야겠어.” 라고 합리적인 추론을 해서
문제를 해결했어요.

🛠️ 두 번째: Toolformer 모델이 스스로 도구를 학습하다
이제 두 번째 대표 연구는 Toolformer입니다. Meta에서 진행한 연구예요. 이 연구는 바로 아래 질문에서 출발했어요:
“LLM이 스스로 학습하면서
어떤 시점에 어떤 도구(API)를 호출해야 할지를
스스로 깨달을 수 있을까?”
🛎️Toolformer 구조 살펴보기
Toolformer의 전체 프로세스는 크게 세 단계로 나눌 수 있어요:
- 프롬프트 안에 도구 호출 구문을 삽입합니다.
예: Joe Biden은 Scranton에서 태어났다 → QA 도구를 호출해서 이 정보를 검증하게 함. - 모델이 다양한 API를 호출하면서 학습 데이터를 생성합니다.
- 이후, 이 응답들이 진짜 유용했는지 아닌지를 평가해서,
유용한 경우만 훈련 데이터에 포함시켜요.

판단”하는 능력이에요. 이걸 위해 모델의 훈련 손실(loss) 을 기준으로 도움이 되는 API 호출은 남기고, 도움이 안 되는 호출은 버리는 필터링 과정도 포함되어 있어요.
예를 들어,
- “Pittsburgh는 ‘Steel City’로 알려져 있다” → 유익함 → 유지
- “Pittsburgh가 미국에 있다” → 너무 당연함 → 제거
이런 식으로 똑똑하게 필터링하는 거예요.
🧠 LLM의 약점
하지만 이 모델들을 현실에서 활용할 때는 단순히 “잘 작동한다”는 것만으로는 부족합니다. 우리가 항상 기억해야 할 건, 언어 모델은 완벽하지 않고, 환각(hallucination) 문제나, 편향(bias), 프롬프트 조작(prompt injection) 같은 취약점이 있다는 사실이에요.
그렇기 때문에 우리는 항상 “이 모델이 지금 왜 이런 말을 하고 있는 걸까?” “어떤 데이터나 구조가 이런 반응을 만들었을까?” 를 끊임없이 되짚고, 검증하고, 평가할 수 있어야 해요.
🧪 LLM 검증과 평가의 중요성
LLM이 똑똑해질수록, 그 출력을 평가하고 검증하는 작업은 더 어려워지고, 동시에 훨씬 더 중요해집니다. 예전처럼 모델 성능을 단순한 정확도로 평가하던 시절은 지났고, 이제는 LLM의 출력이 실제 업무나 학습에 쓰이는 만큼검증 체계, 기준, 지표, 맥락 기반 평가가 정말 중요해졌어요.
🧪 예시: LLM의 환각을 방지하는 방법은?
“Retrieval-Augmented Generation (RAG)”을 사용하는 것이 효과적입니다.
RAG는 이런 구조예요:
- 모델은 외부 데이터베이스(또는 벡터스토어) 에서 관련 정보를 검색하고,
- 그 정보를 바탕으로 텍스트를 생성합니다.
이 방식의 장점은
- 모델은 문장을 유창하게 만드는 데만 집중하고
- 팩트는 외부 데이터에 의존하게 된다는 점이에요.
그래서 만약 데이터가 변경된다면 모델을 다시 훈련할 필요 없이, 데이터만 업데이트하면 되는 구조가 되는 거죠. 실용적이고 강력한 전략입니다.
🔮 LLM의 미래에 대한 질문
:“이제 점점 더 많은 데이터를 사용하고 있는데, 나중엔 쓸 수 있는 데이터가 고갈되지 않을까요?”
- 기업들은 앞으로 라이선스 계약을 통해
콘텐츠를 공식적으로 사용하게 될 가능성이 높고, - 동시에 아직 활용되지 않은 데이터 자산을 가진 기업이
인수나 협업 대상이 될 가능성도 높습니다.
그리고 한 가지 더 흥미로운 트렌드:
“이제는 아주 작은 데이터셋만으로도 특정 업무를 처리하는
작고 정밀한 LLM이 더 많이 연구될 것이다.”
즉, 거대 모델(Giant LLM)에서 벗어나
소형 모델을 어떻게 효율적으로 만들고 활용할 수 있을지에 대한
연구가 늘어날 것이라는 전망이에요.
💡 마지막 질문: LLM은 정말 ‘새로운 발견’을 할 수 있을까?
“수백만 개의 논문 속에 암 치료의 실마리가 흩어져 있다면, LLM이 그것들을 연결해서 새로운 해답을 찾을 수 있을까요?”
“저도 그런 미래가 오길 기대하고 있습니다.”
이미 일부 연구에서 언어 모델 구조를 기반의 원자 수준의 분자 시뮬레이션을 수행해서 소금 결정 구조를 정확히 예측한 사례도 있었어요.
즉, 언어 모델은 이제 단순히 말을 생성하는 것을 넘어 현실 세계의 복잡한 패턴을 이해하고, 예측하는 능력까지 갖춰가고 있어요. 그래서 “LLM이 새로운 과학적 발견에 기여할 날도 멀지 않았다.”는 것이 저의 결론입니다.
🙏 마무리하며
오늘 함께 해주셔서 감사합니다. 질문도, 참여도 모두 너무 좋아서 저도 즐거운 시간이었습니다. LLM을 활용한 새로운 시대, 그 안에서 우리가 어떤 책임감을 가지고 기술을 설계하고, 어떻게 평가하고, 더 나은 방향으로 이끌어갈지를 함께 고민해나가길 바랍니다.
🔮정리
AI 에이전트는 단순한 요청 수행부터 계획 수립, 도구 호출까지 가능한 워크플로우를 의미합니다. 대표적으로 사고와 행동을 결합한 ReAct 모델과 스스로 도구 사용을 학습하는 Toolformer가 있고요. 이러한 시스템은 언어 모델의 고질적인 문제인 환각(hallucination)과 편향, 정보 부정확성을 줄이고자 계속해서 진화하고 있습니다.
특히 ReAct는 생각과 행동을 오가며 문제를 해결하고, Toolformer는 스스로 유용한 API 호출 시점을 학습하는 점이 특징입니다. 향후에는 거대한 모델보다는 작고 정밀한 LLM의 개발이 활발해질 것으로 보이며, 궁극적으로는 LLM이 새로운 과학적 발견에도 기여할 수 있을 것으로 보여요.
.
.
.
AI 시대, 가장 확실한 대비를 위해
지금 바로 배울 수 있는 [ AI ] 관련 강의가 준비되어있어요.
지금 바로 아래에서 관심을 끄는 강의를 눌러 확인해보세요.
 2025 AI시대 일잘러를 위한 2025 AI시대 일잘러를 위한비현실적인 700가지 ChatGPT 활용 바이블 |
 AI로 코딩하는 시대! 비개발자도 할 수 있는 AI로 코딩하는 시대! 비개발자도 할 수 있는Cursor.AI 실전 웹 제작 |

가장 먼저 만나는 Google Gemini |
 초격차 패키지:15개 프로젝트로 실무까지 초격차 패키지:15개 프로젝트로 실무까지끝내는 Dart & Flutter 앱 개발 |
[출처] MIT 6.S191 (Google): Large Language Models






1 thought on “구글 스태프가 알려주는 AI의 미래: 에이전트형 LLM 기술 완전 정복”