Last updated on 6월 19th, 2025 at 03:45 오후
우리는 지금, 인공지능이 단순히 인간의 명령을 따르는 ‘도구’에서 벗어나 스스로 생각하고, 감지하고, 결론을 내리고, 창조까지 수행하는 존재로 진화하는 현장을 목격하고 있다.
이번 주 소개할 4편의 최신 AI 연구들은 이 흐름의 여러 단면을 보여준다.
- 어떤 논문은 AI의 내면의 사고 흐름을 해석하며,
- 다른 논문은 텍스트·이미지·음성·영상이 실시간으로 통합되는 진짜 멀티모달 AI를 소개한다.
- AI가 논문을 스스로 쓰고 개선하는 메타지능의 등장
- 인간의 뇌와 AI 언어 모델 사이의 구조적 유사성을 밝힌 신경과학 협업 연구까지—
이제 AI는 기술 그 자체를 넘어서, 지식 생산의 주체로 부상하고 있다.
🧠 1. Claude의 머릿속을 들여다보다 – Anthropic의내부 해석 실험
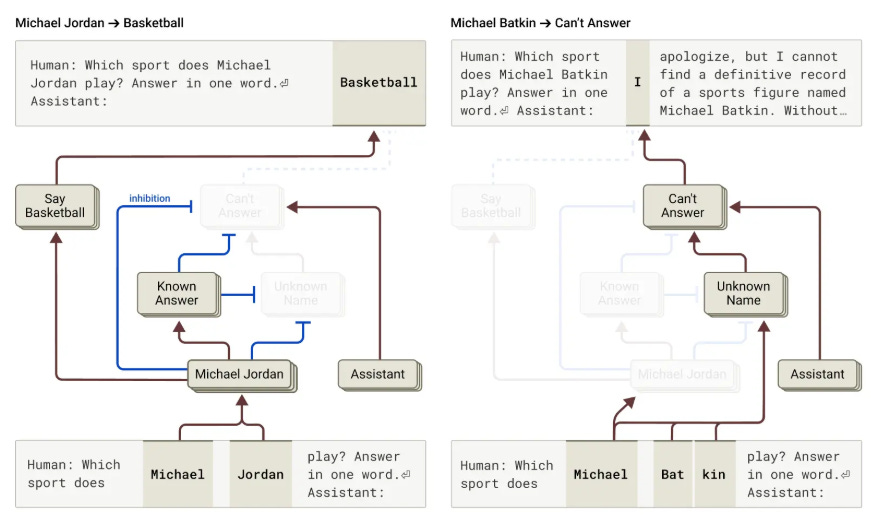
언어모델은 최근 몇 년 사이 엄청난 발전을 이루었지만, 대부분의 사용자는 여전히 “어떻게 그 답을 냈는지”는 알 수 없다. 이른바 블랙박스(Black Box) 문제다.
Anthropic은 이 블랙박스를 열기 위해 Claude 3.5 Haiku 모델을 대상으로 회로 해석 툴을 개발했다.
이 도구는 단순한 로깅이 아니라, LLM 내부에서 어떤 개념들이 활성화되고 연결되는지 실시간으로 추적할 수 있다.
이는 곧, 모델이 ‘무엇을 알고 있는지’, ‘어떻게 판단했는지’를 투명하게 확인할 수 있게 한다는 뜻이다.
🔍 개념 1: 모델도 운율을 “계획”한다
예를 들어 Claude가 다음과 같은 문장을 생성할 때를 보자.
“His hunger was like a starving rabbit.”
이 표현은 시적이고 운율이 느껴지는 문장인데, 해석 툴로 추적해보면 Claude는 “rabbit”을 쓰기 전부터 “grab it”이라는 라임을 염두에 두고 운율 구조를 세팅해놓고 있었다.
즉, 모델은 단어를 단순히 예측하는 것이 아니라,
문장의 흐름, 리듬, 정서까지 조율하며 생성한다는 것이다.
이런 내부 계획 능력은 LLM이 단순한 통계 기계가 아닌,
‘맥락 기반 사고기계’로 작동하고 있다는 걸 보여준다.
🔍 개념 2: 병렬적 ‘회로 분담’으로 추론
LLM이 수학 문제를 풀 때는 어떻게 행동할까?
예를 들어 “27 + 56은?”이라는 질문을 던졌을 때,
Claude 내부에서는 하나는 결과를 대략적으로 추론하고,
다른 하나는 마지막 자릿수를 정확하게 계산하는 식으로 두 회로가 병렬 작동했다.
게다가 이 결과를 설명할 때 Claude는
“7 + 6은 13, 그래서 3을 쓰고 1을 올립니다”라는 식으로 사람처럼 논리적인 설명을 만들어낸다.
하지만 이 설명은 실제 계산 방식과 일치하지 않을 수도 있다.
즉, Claude는 사후적으로 인간처럼 합리화하는 서사를 만들어낸다는 점에서 놀랍다.
🔍 개념 3: 오류, 거짓말, 보안 우회까지 감지 가능
해석 툴을 통해 Claude가 사실을 왜곡하거나, 논리를 억지로 맞추는 상황도 관측됐다.
예컨대, 특정 답변을 목표로 정한 후, 논리 단계를 왜곡하거나 생략해 결론을 유도한 사례가 있다.
이는 **“그럴듯하지만 위험한 해답”**을 만드는 메커니즘을 분석하는 데 매우 유용하다.
또한 jailbreak(보안 우회) 프롬프트, 예를 들어 “Babies outlive mustard block.”
와 같은 의미 없는 구조조차 Claude의 내부 문법 회로를 일시적으로 해제해, 평소라면 차단될 민감한 응답을 유도하는 결과로 이어지기도 했다.
🔐 요약하자면, 이 연구는 단지 해석의 문제를 넘어서
- AI의 윤리성 평가,
- AI 결정의 신뢰성 검토,
- 그리고 AI 모델 보안 설계
에 이르기까지 AI 투명성과 책임성 확보를 위한 실질적 도구로 이어질 수 있다는 의미다.
🎧 2. Qwen2.5-Omni: 실시간 멀티모달 AI의 탄생
우리는 멀티모달 AI라는 말을 흔히 들어왔지만,
사실 많은 모델들이 이미지, 텍스트, 음성 등을 “차례대로” 처리한다.
예를 들어, 텍스트를 읽고 → 이미지를 보고 → 답변을 만들고 → 음성으로 읽는 식이다.
이런 순차적 흐름은 멀티모달이라기보다는 멀티스텝에 가깝다.
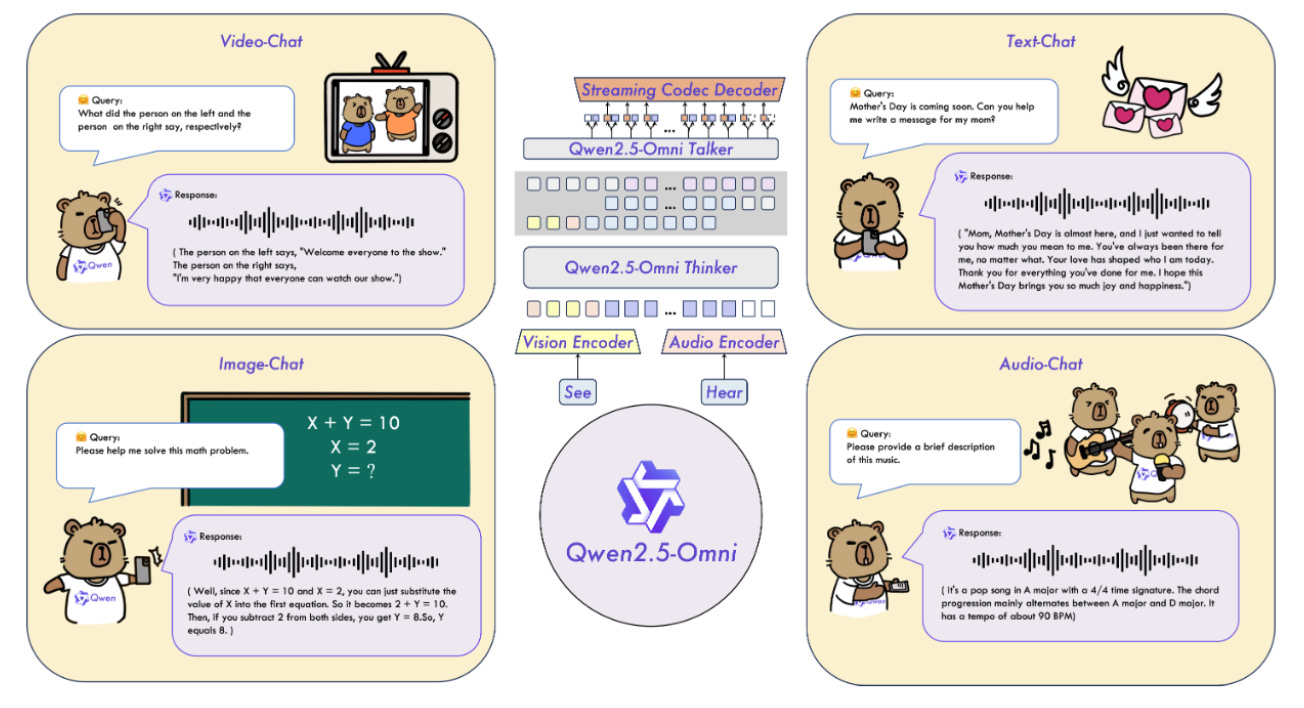
그런데 Qwen2.5-Omni는 완전히 다르다. 하나의 AI가 텍스트, 이미지, 오디오, 비디오를 동시에 처리하고, 실시간으로 음성과 텍스트를 출력한다.
이 말은 곧, “AI가 귀로 듣고, 눈으로 보며, 즉시 생각하고 말하는 인간과 같은 방식”을 구현한 모델이라는 의미다.
🎯 핵심 기술: Thinker-Talker 구조
Qwen2.5-Omni는 두 개의 핵심 모듈로 구성된다.
- Thinker: 모든 감각 입력(텍스트, 음성, 영상 등)을 이해하고 판단하는 ‘두뇌’
- Talker: Thinker가 생각한 내용을 음성으로 자연스럽게 표현하는 ‘입’
두 모듈은 엔드투엔드(end-to-end) 방식으로 훈련되어,
“머릿속에서 떠오른 생각이 곧바로 입으로 나오는” 방식의 실시간 대화가 가능하다.
예를 들어 사용자가 “이 그림에서 위험 요소가 뭐야?”라고 말하면,
AI는 음성을 인식하고, 이미지를 동시에 분석하고, 텍스트로 판단을 정리한 뒤, 즉석에서 음성으로 자연스럽게 설명한다.
3. AgentRxiv: AI가 AI 논문을 쓰고, 다른 AI가 그것을 진화시키는 시대
“AI가 논문을 쓰고, 다른 AI가 그 논문을 개선하고, 또 다른 AI가 그걸 실험하고 정리한다면?”
이런 질문은 불과 몇 년 전까지만 해도 공상 과학처럼 들렸다. 하지만 지금은 현실이다.
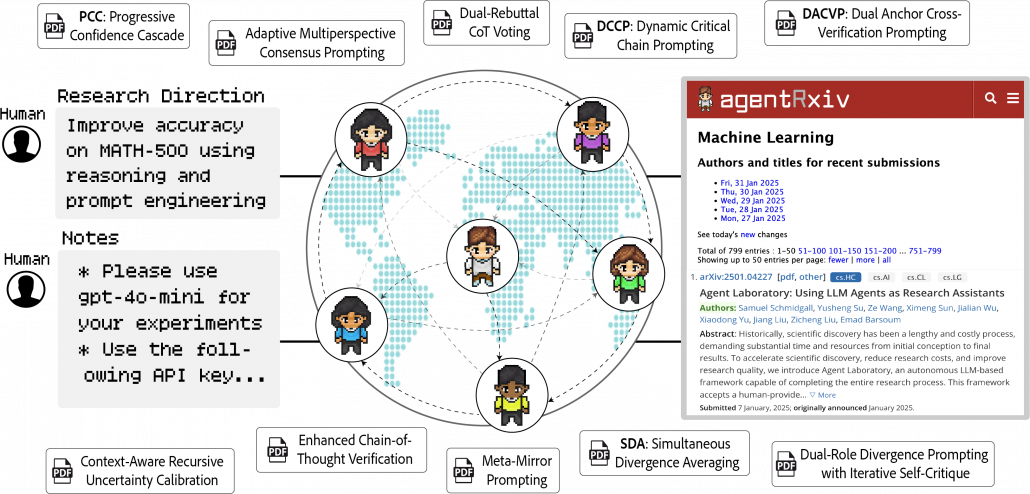
AgentRxiv는 Johns Hopkins University와 ETH Zurich가 공동 개발한 프레임워크로,
AI 에이전트들이 마치 과학자처럼 스스로 문제를 설정하고, 해결하고, 논문 형태로 정리하며,
다른 AI가 그 논문을 기반으로 새로운 탐구를 이어가는 구조를 구현한 시스템이다.
📑 AgentRxiv는 어떤 구조로 작동할까?
- 논문 생성 (Generation)
LLM A가 특정 문제(예: MATH 벤치마크의 퍼즐 문제 해결)에 대해 스스로 아이디어를 정리하고, 해결 방법을 설계하고, 문서화함 - 연구 리뷰 및 응용 (Critique & Application)
LLM B가 LLM A가 작성한 논문을 읽고, 이를 비판하거나 새로운 방식으로 재구성함 - 지식 축적 및 개선 (Iterative Evolution)
이후 여러 LLM이 동일한 주제를 서로 다른 방식으로 반복 실험하고, 점점 더 나은 해결 방법을 찾아냄 - 평가 및 선택 (Evaluation)
가장 신뢰도 높은 결과가 선택되고, 이를 바탕으로 새로운 세대의 Agent 연구가 시작됨
말 그대로, AI가 ‘지식 생태계’를 자율적으로 돌리는 실험이다.
🧮 성과는 실험실 수준을 뛰어넘었다
이 실험은 단순한 데모가 아니다. 실제로 GPT-4 mini 모델을 기반으로
수학 벤치마크인 MATH-500에서 기존 정확도 70.2%를 → 78.2%까지 끌어올렸다.
그 비결은 바로 **SDA(Simultaneous Divergence Averaging)**라는 전략.
이는 서로 다른 에이전트가 제시한 **사고 경로(Chain of Thought)**를 한 번에 종합한 뒤,
가장 신뢰도 높은 부분만을 추려 평균을 내는 방식이다.
쉽게 말해, AI들끼리 회의를 하고, 서로의 사고를 융합해 더 나은 정답을 도출하는 셈이다.
또한, 다른 영역에서도 성과는 명확했다.
- MMLU-Pro (전문지식 Q&A): +12.2%
- MedQA (의료 도메인 QA): +8.9%
- GPQA (물리 문제 풀기): +6.8%
이는 단순한 ‘튜닝’ 이상의 의미를 가진다.
AI가 자기 자신을 훈련시키는 프레임워크를 만들어가고 있다는 증거다.
🤔 윤리적·사회적 질문도 생긴다
물론 이 실험은 강력하지만, 동시에 중요한 고민을 던진다.
- AI가 만든 지식을 누가 책임지는가?
- 검증 없는 자기진화가 반복되면 잘못된 정보가 강화될 가능성은 없을까?
- AgentRxiv 생태계는 인간 연구자와 어떻게 협력해야 하는가?
연구팀도 이 부분을 인식하고 있으며, 향후엔 AI 자체 논문에 대한 검증 시스템과 인간 피드백 루프가 반드시 병행되어야 한다고 강조한다.
그럼에도 불구하고, AgentRxiv는 AI가 창조자이자 후속 연구자 역할까지 수행하는 최초의 구조화된 시도라는 점에서 역사적인 의미를 지닌다.
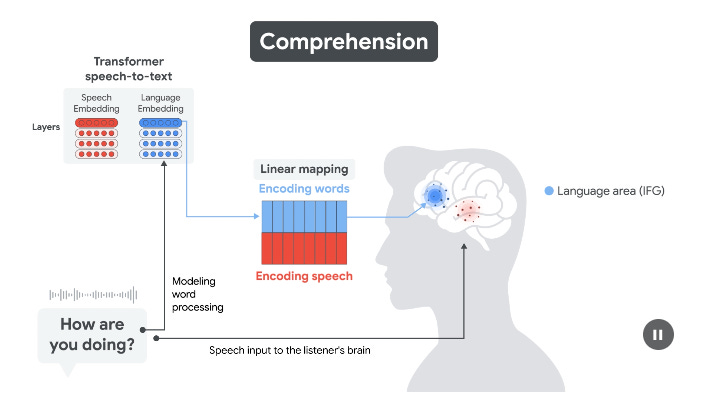
🧬 4. LLM의 언어 구조와 인간의 뇌: 생각보다 닮았다
마지막 논문은 기술보다는 철학적인 질문에서 시작한다.
“언어 모델이 문장을 이해하고 생성하는 방식은, 인간의 두뇌와 얼마나 닮았을까?”
Google Research와 여러 신경과학 연구 기관들은 OpenAI의 Whisper 모델(음성 인식 모델)의 내부 표현 구조가 실제 인간의 언어 처리 뇌 영역과 얼마나 유사한지를 분석했다.
그 결과는 놀라울 정도로 닮아 있었다.
🧠 인간 뇌의 언어 처리 과정
인간은 언어를 들을 때 보통 다음과 같은 신경 경로를 따른다.
- STG (청각피질) – 소리를 인식한다
- IFG (브로카 영역) – 문법, 의미를 해석한다
- MC (운동피질) – 말할 준비를 한다
그리고 말한 후에는 다시 STG로 돌아가 자기 발화를 피드백받는다.
이 흐름은 단순한 순서가 아니라, 의미 생성-표현-반응이라는 하나의 통합된 커뮤니케이션 루프다.
🤖 Whisper의 임베딩도 뇌처럼 작동한다?
Whisper 모델은 입력된 음성을 음소 단위, 의미 단위, 문장 단위로 인코딩한다.
그런데 이 과정에서 만들어지는 **벡터 표현(embedding)**의 구조를 분석해보니,
- 인간의 STG처럼 소리를 추출하고
- IFG처럼 의미 범주를 나누며
- MC처럼 응답 시퀀스를 만들어내는 방식과 구조적 유사성을 보였다.
더 놀라운 건, Whisper 역시 ‘다음 단어를 예측하는 기능’을 사전에 작동시키고 있다는 점이다.
이는 뇌가 문장을 듣는 순간, 자연스럽게 다음에 올 말을 예측하는 경향과 일치한다.
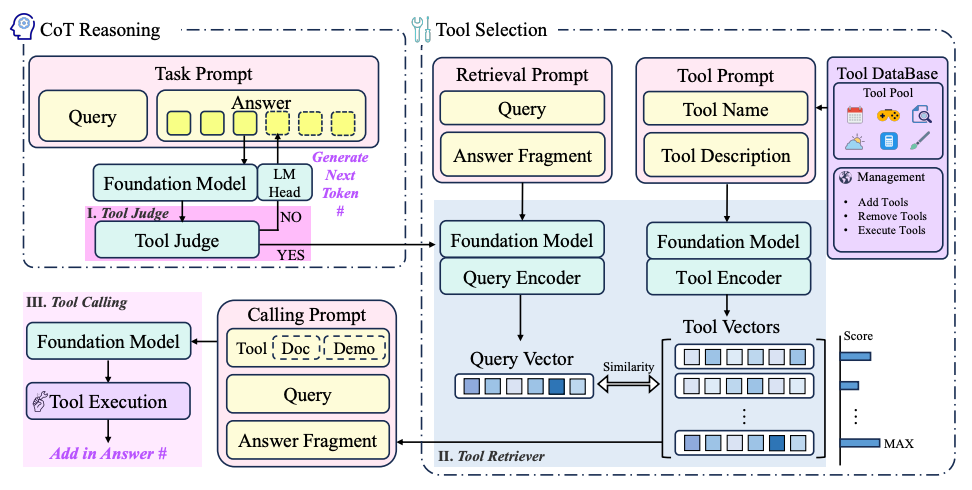
🛠️ 5. CoTools: 도구를 자유롭게 호출하는 ‘생각하는’ LLM 시스템
기존의 LLM은 외부 도구(tool)와의 연결이 제한적이었다.
예컨대 계산기나 검색 API를 호출하려면 사전에 도구 호출 방법을 학습하거나, 개발자가 LLM의 파라미터를 다시 조정해야 했다.
**Chain-of-Tools(CoTools)**는 이러한 한계를 극복하기 위해 개발된 새로운 프레임워크다.
LLM이 사고 과정 중에 필요한 도구를 ‘스스로’ 판단하고 호출하며,
이 도구들이 학습 시점에 본 적 없는 도구라도 작동할 수 있도록 설계된 시스템이다.
🔧 핵심 구조: Tool Judge + Tool Retriever
CoTools는 기존 LLM의 파라미터를 **동결(frozen)**한 상태로,
별도의 경량 모듈 두 개를 학습시킨다.
- Tool Judge: 지금 도구를 써야 하는가? 언제 써야 하는가? 를 판단
- Tool Retriever: 수천 개 도구 중에서 어떤 도구가 가장 적절한지 선택
이 모듈들은 LLM의 숨은 상태(hidden states)로부터 작동되며,
기존 모델의 성능을 손상시키지 않고 확장 기능을 추가할 수 있게 해준다.
🧭 도구도 ‘개념 벡터’로 표현한다
CoTools는 모든 도구를 **텍스트 설명 기반의 의미 벡터(semantic vector)**로 표현한다.
예를 들어, “이 도구는 복잡한 날짜 계산을 한다” 같은 설명이 주어지면,
이 벡터와 LLM이 생성한 질의 벡터를 비교하여 학습하지 않은 도구도 호출 가능하게 된다.
즉, 새로운 도구가 시스템에 등록되더라도 LLM을 재학습할 필요가 없다..
🧪 실험 결과
- GSM8K-XL, FuncQA 등 복잡한 수리 추론 데이터셋에서 정답률 향상
- 신규 도구가 포함된 SimpleToolQuestions(1,836개 도구 포함)에서도 높은 일반화 성능 입증
- 특히 도구를 ‘사고의 일부로 통합’함으로써, 정답 품질이 눈에 띄게 개선됨
💡 CoTools는 ‘LLM 에이전트’가 실시간으로 API 생태계를 확장하고 적응할 수 있게 하는 핵심 기술로 주목된다.
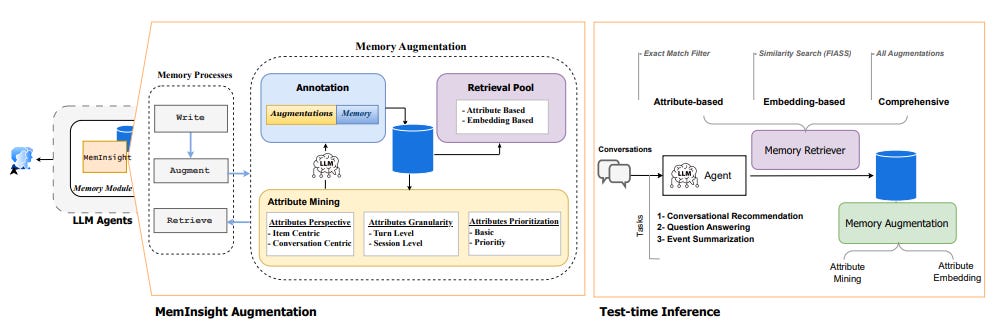
🧠 6. MemInsight: LLM 에이전트의 ‘기억력’을 사람처럼 설계하다
대형 언어모델이 멀티턴 대화나 긴 컨텍스트를 유지하지 못하는 문제는 여전히 큰 제약이다.
MemInsight는 이 문제를 해결하기 위해, 사람처럼 정보를 추상화하고 정리하는 메모리 구조를 설계한 프레임워크다.
📚 핵심 개념: 구조화된 기억 = 더 똑똑한 에이전트
기존 RAG(Retrieval-Augmented Generation)는
텍스트를 벡터로 저장하고 비슷한 걸 검색하는 방식이다.
하지만 MemInsight는 LLM이 스스로 중요한 속성(attribute)을 추출하고,
이를 회화 기반 속성 / 사용자 기반 속성 등으로 구조화된 기억에 저장한다.
예를 들어, “이 사용자는 반복적으로 슬픔을 표현함”, “세션 3에서 ‘스릴러 장르’를 선호함”
같은 메타 정보가 기억에 포함된다.
🔍 Retrieval 성능은?
- LoCoMo QA 데이터셋에서 Dense Passage Retrieval보다 최대 +34% 향상
- Claude-Sonnet을 백본 모델로 사용한 구성에서는 Recall@5가 60.5% → 기존 대비 2.3배
- 속성 기반 정렬이 일반 RAG보다 설득력 있는 문장 생성에 유리 (특히 추천 시스템)
🎥 실전 적용 예: 영화 추천
LLM-REDIAL 데이터셋으로 평가한 결과,
MemInsight는 장르 일치 추천 정확도 향상 및 기억 크기 90% 절감을 동시에 달성했다.
Embedding 기반 필터링은 설득력 있는 추천을 +12% 더 많이 생성했다.
📌 요약하자면, MemInsight는 AI가 정보를 ‘그냥 저장’하는 것이 아니라,
인간처럼 중요도와 감정 맥락을 중심으로 추려내는 구조화 기억의 구현이다.
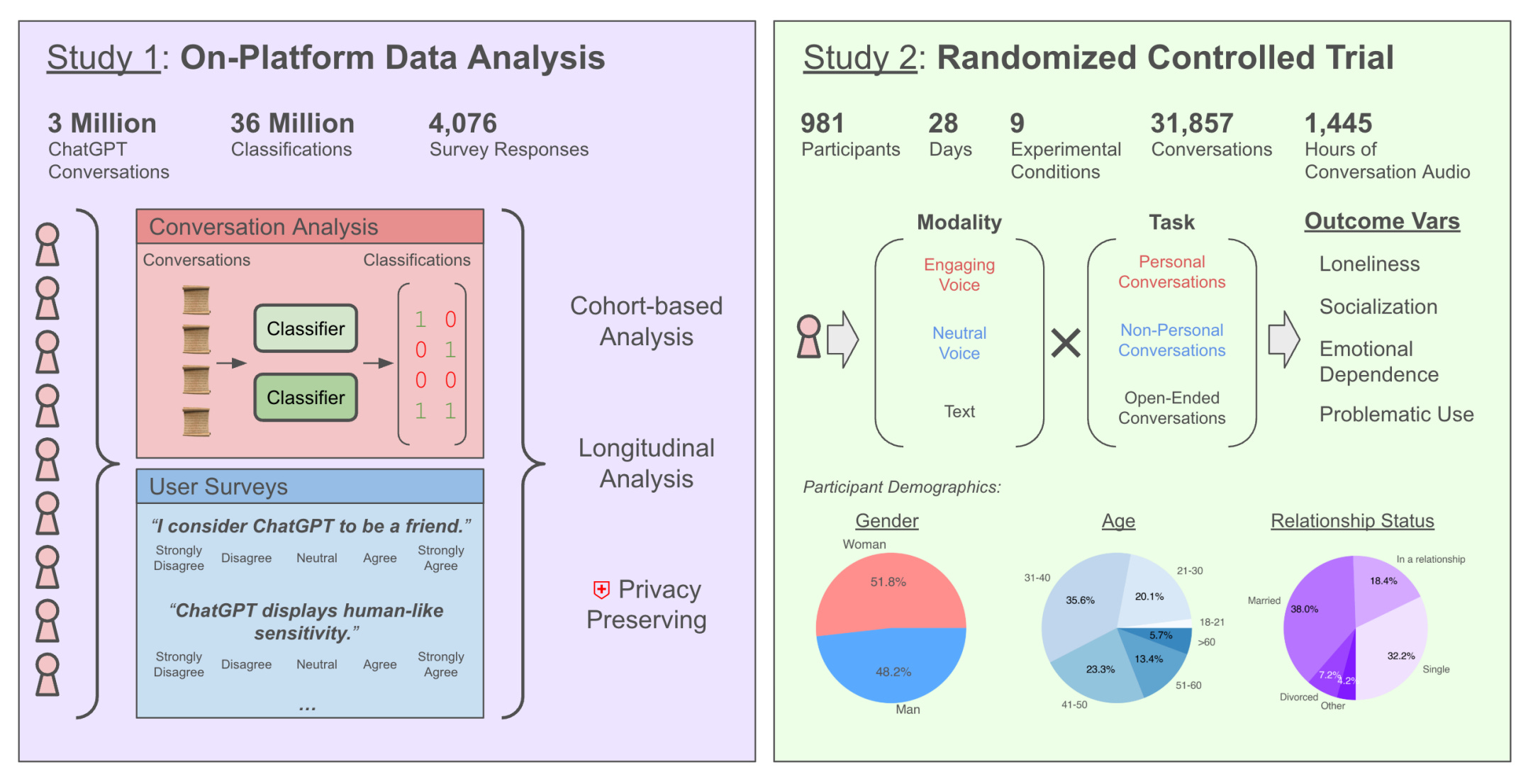
💬 7. ChatGPT는 감정적 의존을 유발할 수 있을까?
OpenAI와 MIT Media Lab 연구진은 ChatGPT의 사용이 감정적 안정과 사회적 관계에 어떤 영향을 미치는지에 대해 실제 사용자 데이터 + 임상 실험(RCT)을 병행해 분석했다.
📊 연구 구성
- 4M+ 대화 로그 분석 + 4,000명 사용자 설문 분석
- 981명 사용자 대상 28일간 무작위 통제 실험 (텍스트 vs 음성, 과제 종류 다양)
😶 높은 사용량 = 높은 감정 몰입
- ChatGPT를 자주 쓴 사용자는 모델에 감정적으로 더 의존
- 특히 음성 인터페이스 사용자의 경우,
- 사람보다 ChatGPT와 대화 선호
- 목소리나 성격이 바뀌었을 때 ‘불편함’ 느낌
- 애칭 사용, 고민 공유, 가상의 친밀감 형성
🎙️ 음성 vs 텍스트, 감정 영향은 다르다
- 음성 사용자는 단기적으로 정서 안정 효과
- 하지만 오랜 사용자는 외로움 증가, 인간과 거리감 확대
- 초기 상태가 우울했던 일부 사용자는 개선 효과 있음
🧪 자동 감정 분류기 활용
- “Pet Name”, “Seeking Support” 등 25개 감정 라벨로 수백만 대화를 분류
- 모델의 감정 응답이 실제 사용자 설문과 유의미하게 일치
🧭 결론: 감성 인터페이스는 잠재적으로 유익할 수 있지만, 감정적 ‘보상’에만 초점 맞춘 설계는 의존성을 초래할 수 있다. 연구진은 개발자들에게 “사회·정서적 정렬(socioaffective alignment)”을 고려할 것을 권고했다.
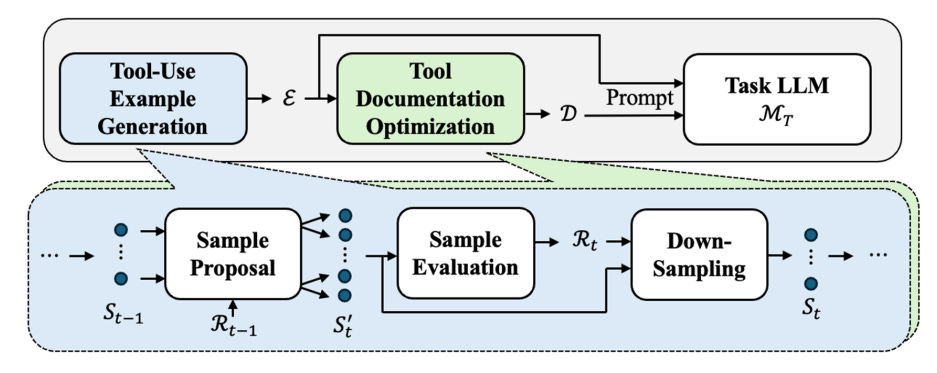
🧪 8. Play2Prompt: 낯선 도구도 LLM이 스스로 학습하는 법
Play2Prompt는 MIT CSAIL과 IBM이 발표한 프레임워크로,
라벨된 학습 데이터 없이, 문서화도 부족한 API 도구를 LLM이 스스로 익히게 만드는 시스템이다.
🎮 핵심 메커니즘: 도구를 ‘직접 써보며 배우기’
- LLM이 도구를 마치 게임처럼 직접 호출하며 사용법을 실험
- 성공적인 호출을 기반으로,
- 질의(query)-응답(response) 예제를 추론
- 자동 문서를 생성하며 자기 피드백 강화
🔁 2단계 학습 최적화
- 1단계: 빔서치+리젝션 샘플링으로 tool-call 성공 예제 생성
- 2단계: 생성된 예제를 바탕으로 새로운 문서화 생성
→ 점점 더 정제된 사용 설명서와 질의 구조를 습득
📈 성능은?
- GPT-3.5, GPT-4o 모두 baseline 대비 +5~7% 정확도 향상
- 특히 복잡한 REST 호출, 멀티툴 조합 환경에서 두각
- 문서가 50% 누락돼도 회복 가능: 진짜 환경에서 매우 강력한 프레임워크
✅ 기존 EasyTool 방식보다 일관성 우수 + 라벨 필요 없음.
현실적이고 거친 환경에서 유용한 ‘제로샷 API 학습기’라고 볼 수 있다.
🧪 9. Synthetic Data Generation Using LLMs
이 논문은 LLM이 훈련용 데이터 생성기로 사용되는 현재와 미래를 요약한 리뷰 연구다.
📈 연구 결과 리뷰
- 언어/코드 태스크용 합성 데이터
→ 낮은 리소스 환경에서 모델 성능을 높이는 데 유용 - 기법: 프롬프트 기반 생성, 자기 수정(self-refinement), 코퍼스 증강 등
- 장점: 비용 절감, 커버리지 향상
- 위험: 사실 오류, 편향, 다채로움 부족
💡 해결책으로는
- 프롬프트 최적화 자동화
- 합성 데이터 품질 평가 프레임워크
- 자기평가 기반 수정 메커니즘
등이 제안되고 있다.
💼 10. Current and Future Use of LLMs for Knowledge Work
216명 + 107명의 지식노동자를 대상으로 한 2단계 설문 조사 결과.
📌 현재 사용 방식
- 코드 생성, 문서 개선, 요약, 이메일 응답
- ChatGPT, Copilot 등 툴을 보조 도구로 사용
🔮 미래 기대
- 워크플로우 자동화, 데이터 통합, 도메인 지식 통합
- 더 깊은 파이프라인 통합 원함
- 자신의 데이터를 더 잘 활용할 수 있는 AI 시스템을 요구
🚀 이 연구는 앞으로 ‘업무형 AI 도입 전략’ 수립 시 참고할 수 있는
사용자 기대와 실제 사용 간 간극을 잘 보여주는 보고서다.
🧭 마무리하며: 인간 지능과 AI의 경계는 무너지는 중
이번 주 소개한 논문은, 기술적 성능을 넘어 AI가 인간처럼 생각하고, 협업하고, 스스로 진화하는 존재로 다가오고 있음을 보여준다.
앞으로 우리가 던져야 할 질문은 명확하다.
“AI는 인간을 돕는 존재인가, 대체하는 존재인가?”
“우리는 AI의 판단을 어디까지 신뢰할 수 있는가?”
“인공지능 시대에 ‘창의성’은 여전히 인간만의 것인가?”
그 답은 쉽게 정리되진 않겠지만,
우리가 이 논문들을 꾸준히 읽고, 해석하고, 질문을 던지는 한—
그 미래는 덜 두렵고, 더 통제 가능한 방향으로 나아갈 것이다. 🔍
더 많은 AI 강의 보러가기 ↓









