Last updated on 3월 25th, 2025 at 10:33 오후
강화학습으로 해결할 수 있는 문제 유형으로는 무엇이 있을까?

알파고가 사람을 이긴 게 놀랄 일인 이유
머신러닝에 대한 사람들의 관심이 높아진 시점은 알파고가 이세돌 9단을 상대로 대국에서 승리한 2016년부터일 것입니다. 이를 두고 ‘알파고 쇼크’라고 할 만큼 사람들은 컴퓨터 프로그램에게 패배한 사실에 대해 큰 충격을 받았는데요. 그 이유는 바둑이라는 종목은 경우의 수가 매우 많아서 제 아무리 컴퓨터라 하더라도 인간을 상대로 컴퓨터 프로그램이 승리할 수 없을 것이라 보았기 때문입니다. 하지만 결국 심층 강화학습 알고리즘을 통해 학습한 알파고는 승리를 거두었습니다. 그렇다면 알파고의 학습 방식 중 하나인 ‘강화학습(Reinforcement Learning)’이라는 건 정확히 무엇일까요?
강화학습은 가장 좋은 행동을 찾기 위한 학습법
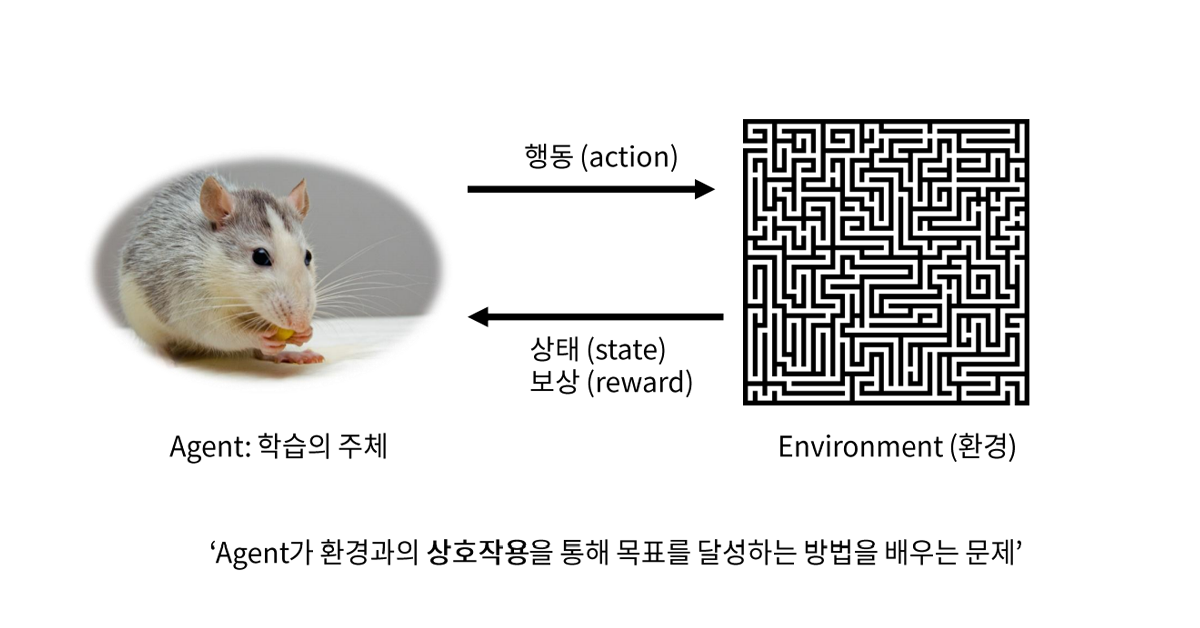 강화학습은 머신러닝(기계학습)의 한 방식으로, 에이전트(agent)라는 학습의 주체가 환경과 상호작용하면서 목표를 달성하기 위해 학습하는 것을 의미합니다. 쉽게 말하면, 기계는 주어진 조건에서 문제를 해결하기 위한 여러 경우의 수를 실행합니다. 이후 행동에 대한 보상(Reward)을 받으면서 목표 달성을 위한 최적의 행동이 무엇인지 찾아나가는 것입니다.
강화학습은 머신러닝(기계학습)의 한 방식으로, 에이전트(agent)라는 학습의 주체가 환경과 상호작용하면서 목표를 달성하기 위해 학습하는 것을 의미합니다. 쉽게 말하면, 기계는 주어진 조건에서 문제를 해결하기 위한 여러 경우의 수를 실행합니다. 이후 행동에 대한 보상(Reward)을 받으면서 목표 달성을 위한 최적의 행동이 무엇인지 찾아나가는 것입니다.
관련 글 더 보기 : 머신러닝과 딥러닝, 아직도 헷갈린다고?
강화학습으로 해결할 수 있는 문제 유형은?
1. 특정 행동에 대한 좋고 나쁨을 평가하는 보상이 주어진다.
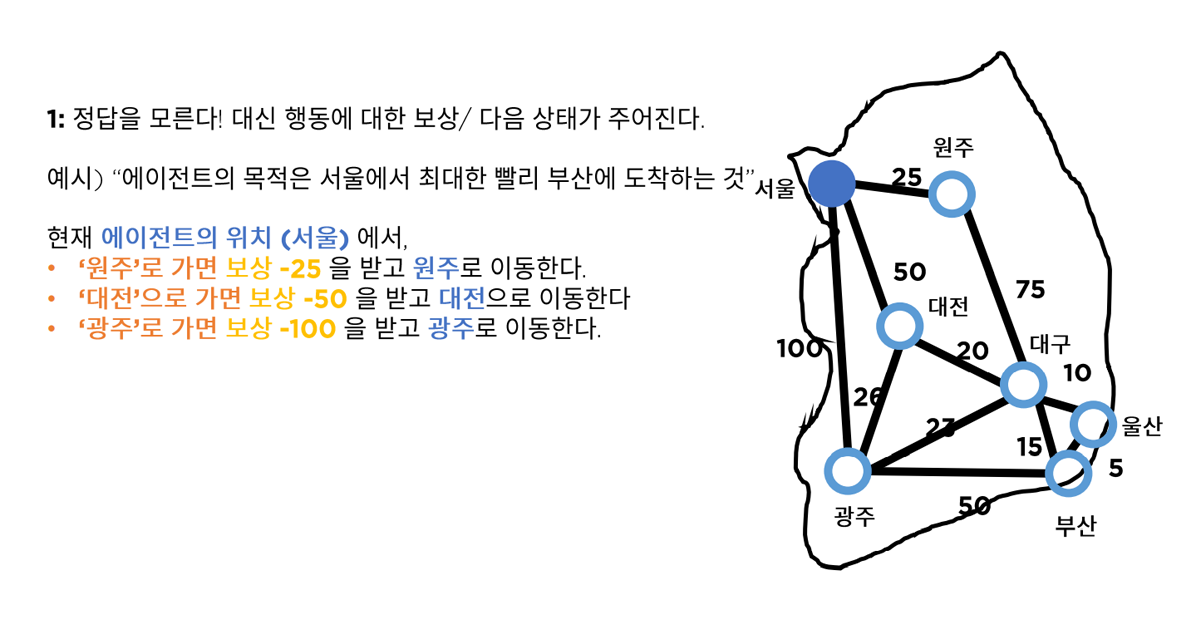 정답은 정해져 있지 않은 상황에서, 보상을 통해 행동에 대해 평가하는 경우입니다. 예를 들어, 에이전트의 목표가 서울에서 최대한 빠르게 부산에 도착하는 것이라고 해봅니다. 부산까지 도착하기 위해 중간 지점을 통과해야 한다고 할 때, 경우의 수는 다음과 같이 내려볼 수 있습니다.
정답은 정해져 있지 않은 상황에서, 보상을 통해 행동에 대해 평가하는 경우입니다. 예를 들어, 에이전트의 목표가 서울에서 최대한 빠르게 부산에 도착하는 것이라고 해봅니다. 부산까지 도착하기 위해 중간 지점을 통과해야 한다고 할 때, 경우의 수는 다음과 같이 내려볼 수 있습니다.
- 서울에서 원주로 이동한다 : 보상 -25를 받는다
- 서울에서 대전으로 이동한다 : 보상 -50을 받는다
- 서울에서 광주로 이동한다 : 보상 -100을 받는다
에이전트는 각각의 행동에서 받는 보상을 통해 문제 해결을 위한 최적의 방법을 학습하게 됩니다.
2. 현재의 의사결정이 미래에 영향을 미친다.
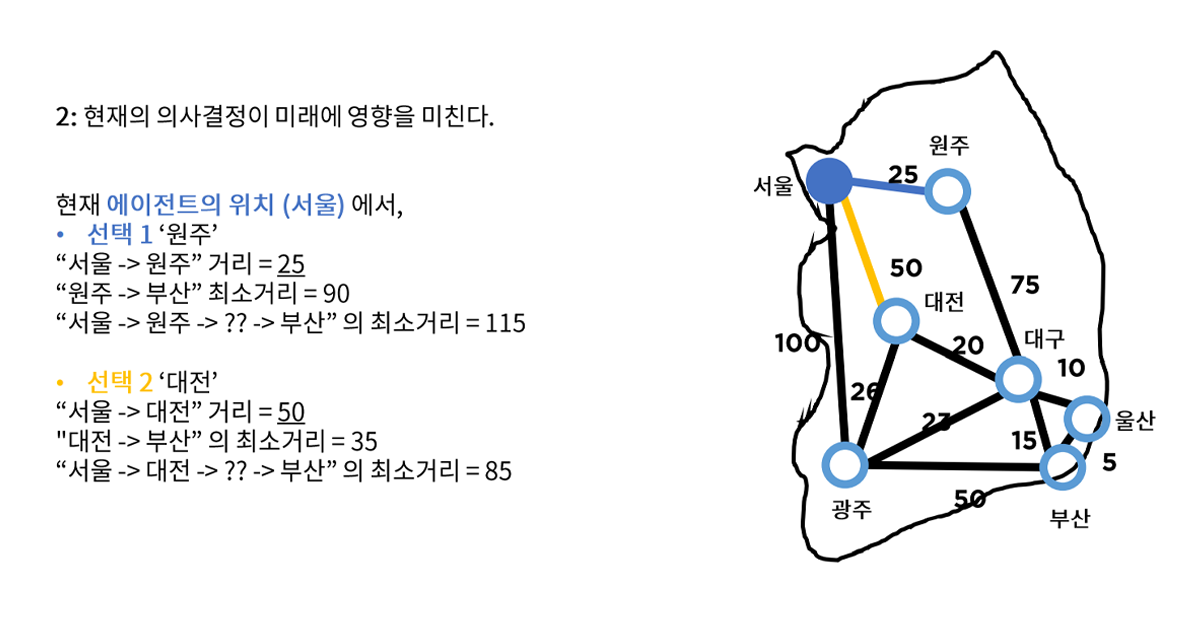 지금 하는 행동이 이후의 결과값에 영향을 미치는 경우입니다.
지금 하는 행동이 이후의 결과값에 영향을 미치는 경우입니다.
- 서울에서 원주로 이동한다 : 보상 -25, 최소거리 100km
- 서울에서 대전으로 이동한다 : 보상 -50, 최소거리 120km
- 서울에서 광주로 이동한다 : 보상 -100, 최소거리 150km
서울에서 어떤 중간 지점을 통과할 것인지에 대한 현재의 의사결정이 이후의 보상과 최소거리, 소요시간 등에 영향을 미치게 됩니다.
3. 문제의 구조를 사전에 알 수 없다.
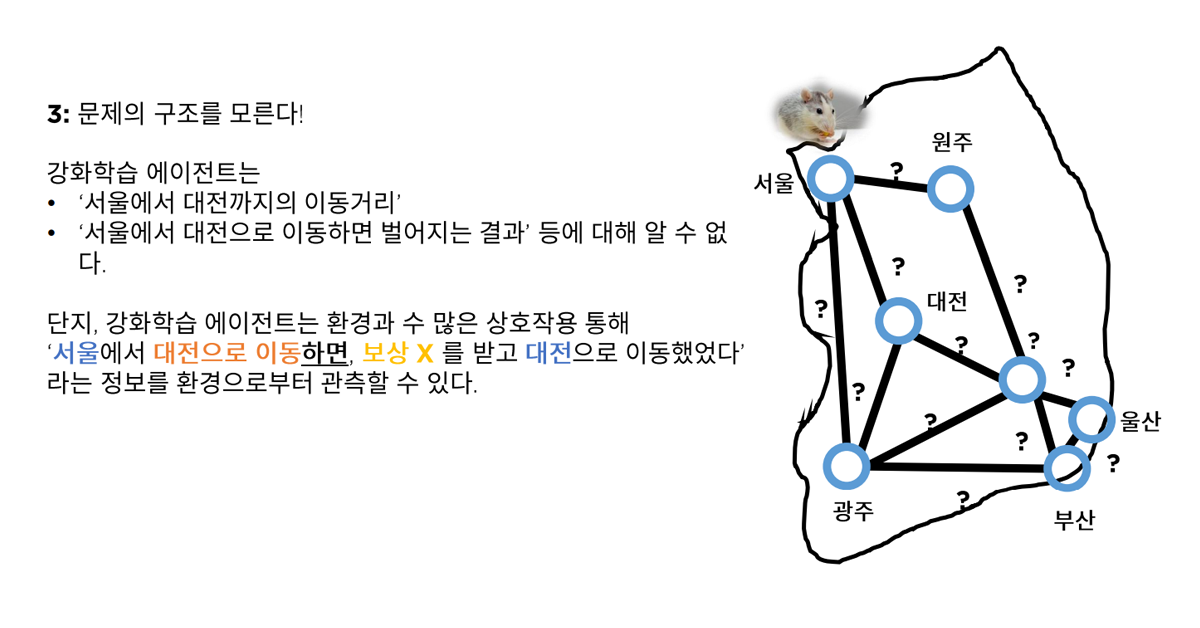 강화학습 과정에서 에이전트는 서울에서 대전까지의 이동거리가 어느 정도인지, 이동할 때 생기는 결과값이나 변수는 어떻게 되는지 사전에 정보를 제공 받을 수 없습니다. 따라서 주어진 환경과의 수많은 상호작용을 거쳐 보상 및 결과 정보를 취합하여 학습하게 됩니다. 이러한 과정을 반복하여 최종적으로 문제를 해결하는 것이죠.
강화학습 과정에서 에이전트는 서울에서 대전까지의 이동거리가 어느 정도인지, 이동할 때 생기는 결과값이나 변수는 어떻게 되는지 사전에 정보를 제공 받을 수 없습니다. 따라서 주어진 환경과의 수많은 상호작용을 거쳐 보상 및 결과 정보를 취합하여 학습하게 됩니다. 이러한 과정을 반복하여 최종적으로 문제를 해결하는 것이죠.
강화학습의 기본 개념 간단하게 정리하기
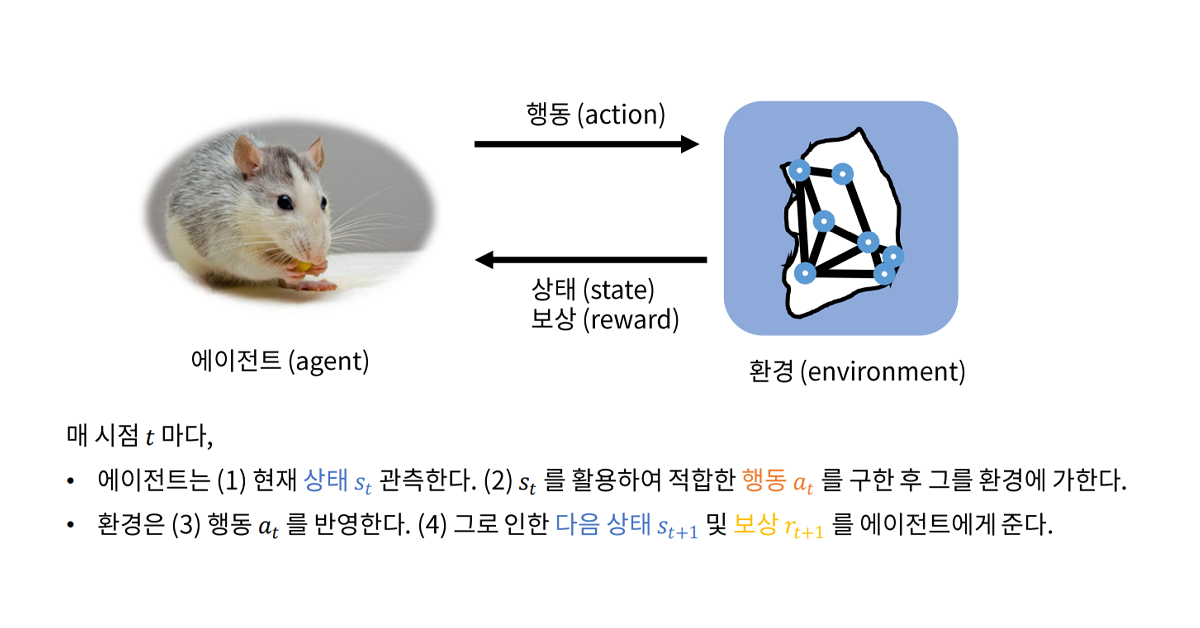
- 보상(Reward) : 특정 행동에 대해 하나의 숫자로 표현되는 평가 지표
- 상태(State) : 현재 상황을 기술하는 정보 (ex. 에이전트의 위치)
- 정책함수(Policy Function) : 특정 상태(State)에서 에이전트가 행동하는 방식 결정
- 가치함수(Value Function) : 각각의 상태와 행동이 얼마나 좋은지 추산 및 평가
- 모델(Model) : 에이전트가 학습 과정에서 추측하는 환경
더 많은 AI 강의가 궁금하다면? ↓








