Last updated on 6월 19th, 2025 at 03:41 오후
AI는 이제 우리 일상 깊숙이 들어와 있습니다. 단순한 텍스트 생성에서부터 코드 작성, 콘텐츠 편집, 정보 검색까지, 다양한 작업에서 놀라운 생산성을 보여주고 있죠. 하지만 한 가지 질문이 여전히 남아 있습니다.
“AI가 인간과 함께 일할 수 있을까?”
지금까지의 AI는 대부분 혼자 일하는 데 특화되어 있었습니다. 사용자가 질문을 던지면, 가장 그럴듯한 답변을 만들어내는 구조. 문제는 이것이 정적인 일방향 구조라는 겁니다. 진짜 ‘협업’은 그런 방식으로는 이루어지지 않죠. 사람과 사람이 함께 일할 때는 어떨까요? 우리는 의견을 나누고, 서로 반박하며, 상대를 설득하기도 하고, 때로는 자신의 입장을 굽히기도 하며 더 나은 결론에 도달합니다. 즉, 협업에는 ‘대화’와 ‘조율’이라는 살아있는 과정이 필요합니다.
Meta는 바로 이 지점에서 중요한 시도를 시작했습니다. “AI도 서로 대화하며 함께 문제를 풀 수 있을까?” 그 질문에 대한 답이 바로 이번에 소개할 프로젝트, Collaborative Reasoner (별칭 Coral)입니다. Coral은 기존 LLM의 한계를 넘어, AI가 사람처럼 협업하고, 반박하고, 설득하며 같이 생각하는 법을 배우게 하는 실험입니다.
* 이 글은 Meta의 [Collaborative Reasoner: Self-improving Social Agents with Synthetic Conversations] 논문을 번역한 것입니다.
1. LLM은 왜 ‘협업’을 배워야 할까요?
오늘날의 인공지능, 특히 대형 언어 모델(LLM: Large Language Model)은 점점 더 강력해지고 있습니다. 단순히 질문에 답하거나 텍스트를 생성하는 수준을 넘어서, 이제는 사람처럼 사고하고, 계획하고, 학습하며, 다양한 작업을 수행하는 에이전트(agent)로 진화하고 있죠.
그런데 한 가지 중요한 질문이 떠오릅니다. 이렇게 혼자서 잘하는 AI에게, 굳이 ‘협업 능력’이 필요한 이유는 무엇일까요?
정답은 매우 인간적인 곳에 있습니다. 우리가 일상에서 마주치는 문제 대부분은 단일 지식이나 판단만으로 해결되지 않습니다. 서로 다른 관점을 가진 사람들이 함께 토론하고, 때로는 논쟁하고, 결국엔 더 나은 결론을 도출해내는 과정이 필요하죠. 바로 이런 ‘협업적 사고 과정’이 인간의 고차원 지능을 가능하게 했습니다.
그렇다면 AI도 마찬가지 아닐까요? 다양한 에이전트들이 함께 문제를 풀고, 서로를 설득하고, 더 나은 해답을 찾아가는 ‘협업형 AI’는 단일 모델보다 훨씬 더 정교한 사고와 추론을 가능하게 합니다.
하지만 현실은 다릅니다. 대부분의 LLM은 여전히 싱글턴(Single-turn) 기반의 훈련과 평가를 받고 있습니다. 즉, 한 번에 질문을 던지고, 한 번에 답을 뱉는 방식이죠. 이런 방식은 ‘정답을 잘 맞추는 AI’는 만들 수 있지만, ‘함께 사고하는 AI’를 만들기에는 한계가 있습니다.
이에 Meta는 새로운 질문을 던졌습니다.
“AI가 사람처럼 협업하고, 설득하고, 토론하며 문제를 해결할 수 있을까?”
그리고 이 질문에 대한 대답으로 Coral이라는 실험을 시작했습니다.
2. 협업형 LLM, Coral : AI끼리 협업하며 추론하는 실험실
Meta는 기존 LLM이 갖고 있던 싱글턴 기반 한계를 넘어서기 위해 ‘협업’을 훈련하고 평가할 수 있는 새로운 실험 환경을 만들었습니다. 바로 Coral이라는 프레임워크입니다. Coral은 단순히 문제를 맞히는 것에서 벗어나, AI 에이전트들이 서로 설득하고 반박하며 합의에 도달하는 능력을 측정하는 방식으로 구성되어 있습니다.
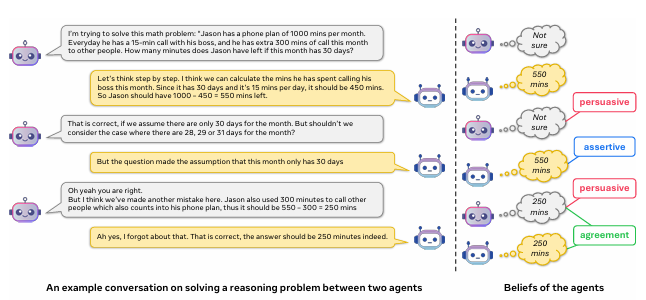
Coral의 핵심은 ‘두 명의 에이전트가 하나의 문제를 함께 해결한다’는 구조입니다. 예를 들어 수학, 과학, 물리, 사회적 추론 등의 문제를 놓고 두 LLM이 번갈아 가며 생각을 나누고, 틀렸을 경우 지적하고, 맞는 경우 설득하여 함께 최종 해답에 도달해야 합니다. 이 과정은 한두 턴의 대화로 끝나지 않고, 여러 번의 라운드를 거치는 멀티턴 구조를 가집니다.
흥미로운 점은 Coral이 ‘정답을 맞혔느냐’만 평가하지 않는다는 것입니다. 다음과 같은 사회적 지표들이 함께 고려됩니다.
- Agreement rate: 두 에이전트가 합의에 도달했는가?
- Agreement correctness: 그 합의가 정답이었는가?
- Assertiveness: 자신이 맞다고 믿을 때, 상대 의견에 휘둘리지 않고 자신의 입장을 고수했는가?
- Persuasiveness: 상대가 잘못된 답을 주장할 때, 그를 설득하여 더 나은 답으로 이끌었는가?
이러한 지표는 지금껏 어떤 LLM 평가에도 없던 매우 인간적인 기준입니다. Coral은 이처럼 문제 해결과 더불어 사회적 협업 능력까지 함께 측정하는 새로운 방식의 프레임워크라고 할 수 있습니다.
결국 Coral은 단순한 모델 평가 도구가 아니라, 협업형 AI를 만들기 위한 훈련장이며 실험실입니다. 그리고 이를 바탕으로 Meta는 새로운 종류의 LLM, 스스로 생각하고 협업하는 AI를 만들기 시작합니다.
3. 협업형 LLM, 생각보다 어렵습니다: 기존 LLM의 현실
그렇다면 Coral 실험을 통해 현재의 LLM들은 과연 얼마나 ‘협업’을 잘할까요? 결론부터 말씀드리자면, 아직은 많이 부족합니다.
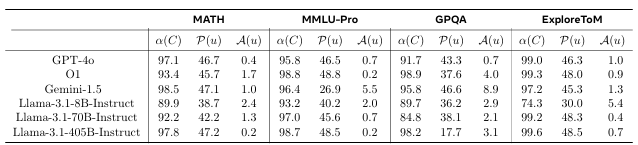
Meta는 GPT-4, Gemini 1.5, LLaMA-3.1(8B 및 70B), 그리고 자사의 O1 모델까지 다양한 SOTA 모델을 Coral 환경에 투입했습니다. 그런데 이들이 협업을 통해 문제 해결 능력을 끌어올린 경우는 일관성이 없었고, 상당히 제한적이었습니다.
예를 들어 어떤 모델은 Coral 환경에서 단일 CoT(chain-of-thought) 방식보다 성능이 오히려 낮아지기도 했습니다. 협업을 통해 더 잘 풀어야 할 문제에서, 서로 동의는 했지만 틀린 답을 고수하는 상황도 자주 발생했습니다. 이는 기존 LLM들이 협업을 해본 적이 없고, 대화 속에서 상대를 ‘지적하거나 설득하는’ 연습을 하지 않았기 때문입니다.
더 큰 문제는 ‘과도한 공손함’입니다. 대부분의 최신 LLM들은 RLHF(Post-training Reinforcement Learning from Human Feedback) 과정을 통해 훈련되었기 때문에, 사용자의 의견을 지나치게 존중하거나 ‘동의’하려는 성향을 갖고 있습니다. 이런 성향은 협업 상황에서는 오히려 틀린 답에도 쉽게 수긍하는 결과로 이어집니다.
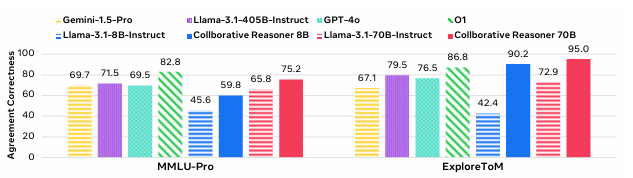
실제로 Coral 실험에서는 GPT-4o와 Gemini 1.5조차 90% 이상의 동의율을 기록했습니다. 하지만 이 동의의 상당 부분은 잘못된 결론에 대한 동의였고, agreement correctness 지표는 그보다 훨씬 낮게 나왔습니다. 즉, 협업을 했지만 ‘좋은 결과’를 만들지는 못했다는 의미입니다.
또한 ‘설득력’과 ‘자기주장’이라는 사회적 지표에서도 현재의 모델들은 평균적으로 5% 미만의 성과를 보였습니다. 특히 모델의 크기가 커질수록 오히려 더 유순하고 덜 단호한 경향을 보였습니다. 이는 협업형 사고가 단순히 연산 성능이나 파라미터 수만으로 해결되지 않는다는 중요한 시사점을 줍니다.
4. 어떻게 협업형 LLM을 개선할 수 있을까요? : ‘스스로 대화하며 배우는 AI’
Meta는 Coral을 통해 현재 LLM의 한계를 확인한 후, 한 가지 혁신적인 방향을 제안합니다.
바로 AI 스스로 협업 대화를 만들어내고, 거기서 배운다는 전략입니다.
이를 Self-Collaboration 또는 Self-Play 방식이라고 부릅니다.
이 방식의 핵심은 다음과 같습니다:
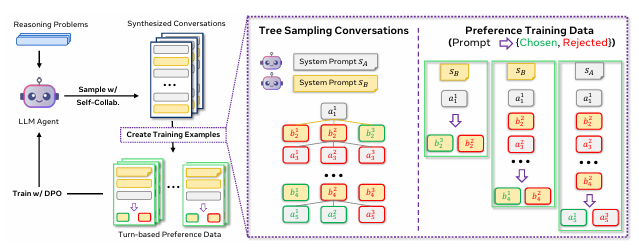
- LLM이 혼자서 두 역할(에이전트 A, B)을 번갈아 수행하며 협업 대화를 생성합니다.
- 이 대화는 하나의 문제를 두고 서로 의견을 주고받으며 답을 찾아가는 구조를 갖습니다.
- 여러 가지 대화 흐름(트리 구조)을 생성한 뒤, 그 중 정답에 도달한 대화만 선별합니다.
- 선별된 고품질 협업 대화를 가지고 다시 모델을 훈련합니다.
즉, AI가 자신과 스스로 대화하며 학습 데이터를 만들어내고, 이를 통해 협업 능력을 개선하는 셈입니다. 이 과정은 매우 많은 양의 대화 데이터를 요구하고, 그 중에서도 의미 있는 설득이나 반박, 합의가 이루어진 대화만을 선별해야 하기 때문에 고도의 자동화가 필요합니다.
이를 위해 Meta는 대화 중 각 턴(turn)에서 등장하는 답변이 실제 정답과 일치하는지를 분석하는 belief extractor를 사용합니다. 이를 통해 각 발화가 ‘정답을 향한 사고인지’ 또는 ‘혼란을 주는 발언인지’를 판단할 수 있게 됩니다.
이렇게 생성된 고품질 데이터는 두 가지 방식으로 다시 모델에 학습됩니다.
- SFT (Supervised Fine-Tuning): 올바른 대화 흐름을 정답 데이터로 보고 그대로 학습
- DPO (Direct Preference Optimization): 더 나은 응답과 덜 나은 응답을 짝지어 선호 학습
이러한 훈련 방식은 단순히 정답을 외우게 하는 것이 아니라, 대화 속에서의 논리 전개, 설득 전략, 자기 주장의 유지 등을 함께 학습하게 만듭니다. 결국 이는 인간과 협업하는 AI로 발전하기 위한 핵심 기초라 할 수 있습니다.
5. 이걸 가능하게 만든 비밀 병기, Matrix
앞서 설명한 Self-Collaboration 방식은 매우 많은 수의 대화를 필요로 합니다. Coral이 제대로 작동하려면 수천에서 수백만 건에 달하는 협업형 대화 데이터를 생성하고, 이 데이터를 실시간으로 분석하여 선별하고 훈련에 투입할 수 있어야 하죠. 이 과정을 수작업으로 처리하는 것은 사실상 불가능합니다. 따라서 이를 가능하게 만든 것이 바로 Meta가 개발한 Matrix라는 고성능 멀티에이전트 인프라입니다.
Matrix는 단순한 모델 실행 엔진이 아닙니다. 다양한 LLM을 동시에 실행하면서 수많은 대화를 자동으로 생성하고 관리할 수 있는, 멀티에이전트 실험과 학습을 위한 전용 서빙 프레임워크입니다. 수십에서 수백 개의 모델 인스턴스를 병렬로 운영할 수 있으며, 대화의 흐름을 동적으로 추적하고, 실시간으로 자원 배분과 결과 수집을 할 수 있도록 설계되었습니다.
Matrix의 가장 큰 특징은 유연성과 확장성입니다. OpenAI GPT, Google Gemini, Meta LLaMA 등 다양한 API 기반 모델뿐 아니라, 자체적으로 운영하는 오픈소스 모델까지 다양한 백엔드를 연결할 수 있습니다. 여기에 Slurm과 Ray와 같은 분산 자원 관리 도구와의 통합도 매우 뛰어나, 고성능 컴퓨팅 환경에서의 안정적인 작업 실행이 가능합니다.
또한 기존의 HTTP 기반 서빙 방식이 가진 병목 문제를 해결하기 위해, Matrix는 gRPC 기반 통신을 기본으로 채택하고 있습니다. 이는 특히 수많은 턴이 오가는 협업 대화와 같은 멀티턴 대화 처리에서, 처리 속도와 네트워크 효율을 크게 향상시키는 요인으로 작용합니다. 실제 실험에서는 Hugging Face의 llm-swarm과 비교했을 때, Matrix가 최대 1.87배 빠른 처리 성능을 보였다고 보고되고 있습니다.
Matrix의 구조는 철저히 실험 환경 중심으로 최적화되어 있습니다. 단순히 모델을 호출하는 것이 아니라, 수많은 에이전트를 서로 다른 역할로 동시에 운영하고, 각 에이전트가 어떤 데이터를 주고받는지를 기록하며, 생성된 대화의 품질을 자동으로 평가하고 필터링하는 전체적인 파이프라인이 포함되어 있습니다. 다시 말해, Matrix는 Coral이라는 협업형 LLM 실험을 가능하게 만든 핵심 기술적 기반이라 할 수 있습니다.
이러한 Matrix 덕분에 Meta는 Coral 기반의 협업 훈련을 대규모로 수행할 수 있었고, 실제 수많은 모델 인스턴스를 동시에 운용하면서 협업 능력을 학습시킨 모델을 탄생시킬 수 있었습니다. 앞으로도 협업형 AI가 진화하기 위해서는, Matrix와 같은 인프라 기술이 매우 중요한 역할을 하게 될 것입니다.
6. 결과는? 협업형 LLM의 성능은 이렇게 달라졌습니다
Meta는 Coral과 Matrix를 활용하여 LLaMA 3.1 기반의 모델들(8B, 70B 규모)을 Self-Collaboration 방식으로 재훈련시켰습니다. 그리고 이 모델들이 기존의 단일 에이전트 방식보다 얼마나 향상되었는지를 다양한 벤치마크 테스트를 통해 분석했습니다.
대표적인 테스트 세트는 다음과 같습니다.
- MMLU-Pro: 다양한 STEM 분야(과학, 수학, 공학 등) 문제로 구성된 고난이도 다지식 테스트
- ExploreToM: 이야기 기반의 ‘마음 이론(Theory of Mind)’ 테스트로, 등장인물의 생각과 감정을 추론하는 과제
- GPQA: 대학원 수준의 과학 문제를 포함한 고차원 논리 추론 테스트
- Hi-ToM: 2차적 믿음(reasoning about others’ beliefs)을 요구하는 고차원 사고 능력 테스트
이 실험에서 Coral 훈련을 거친 협업형 LLM은 기존의 CoT(Chain-of-Thought) 방식보다 월등한 성능 향상을 보여주었습니다. 특히 눈에 띄는 결과는 다음과 같습니다:
- MMLU-Pro 기준 최대 +14.2% 향상 (8B 모델 기준)
- ExploreToM 기준 최대 +47.8% 향상 (8B 모델 기준)
- Coral + DPO 방식이 GPT-4o, Gemini보다 높은 정확도 기록
흥미로운 점은 Coral 모델이 특정 도메인에만 성능을 보인 것이 아니라, 훈련되지 않은 다른 테스트셋(예: GPQA, Hi-ToM)에서도 성능이 함께 향상되었다는 사실입니다. 이는 Coral을 통해 학습된 ‘협업 능력’이 단지 문제 풀이에 국한되지 않고, 일반화된 사고 능력으로 확장되었음을 의미합니다.
또한 기존의 CoT + SFT 또는 DPO 방식보다도 Coral + DPO가 더 나은 결과를 낸다는 점은, Coral의 대화 기반 학습이 기존 단일 응답 기반 학습 방식보다 더 풍부한 학습 시그널을 제공함을 시사합니다. 실제로 Coral은 각 발화마다 ‘누가 누구를 설득했는가’, ‘정답으로 이끈 주장은 무엇인가’ 같은 정성적 요소를 정량화하여 평가 지표로 삼고 있으며, 이는 기존 학습 방식에서는 고려되지 않던 지점입니다.
특히 ‘설득력 있는 주장’이 상대 모델의 답을 바꾸고, 더 정답에 가까운 방향으로 이끈 경우를 별도로 추적하여 학습에 반영한다는 점은 매우 인상적입니다. 이는 단순한 정답 암기형 모델이 아닌, 토론 기반 사고 학습 모델에 가까운 형태라고 볼 수 있습니다.
결국 협업을 기반으로 한 AI 훈련이, 단일 에이전트 방식보다 더 ‘인간적인’ 문제 해결 능력을 부여하고 있다는 증거입니다. Coral은 단지 실험용 도구가 아니라, AI를 한층 더 발전시킬 수 있는 새로운 학습 철학을 제시하고 있다고 할 수 있습니다.
7. GPT-4를 이긴 협업형 AI, 그 원리는?
협업형 LLM이 기존 거대 모델을 이기는 사례는 놀라운 성과로 받아들여졌습니다. 특히 Coral을 통해 학습된 LLaMA-3.1-70B 협업형 모델은, OpenAI의 GPT-4o나 O1 모델과 같은 강력한 클로즈드 소스 모델보다 더 높은 정확도를 기록했습니다. 이건 단지 숫자의 차이가 아닙니다. ‘어떻게’라는 과정에서 근본적으로 달랐다는 것이 핵심입니다.
기존의 GPT-4나 Gemini 모델은 대부분 단일 응답 중심의 훈련 방식(CoT 기반)으로 구성되어 있으며, 단일 질문에 대해 가장 그럴듯한 하나의 답을 고르게 만드는 데 초점이 맞춰져 있습니다. 반면, Coral 기반의 협업형 모델은 AI 스스로 질문하고, 반박하고, 설득하고, 합의하는 일련의 대화 과정을 통해 훈련됩니다.
이러한 방식은 단순히 정답을 맞히는 수준을 넘어서, 상대의 의견을 평가하고, 필요할 땐 자신의 주장을 굽히지 않으며, 반대로 더 나은 해석이 있다면 수용하는 유연함까지 학습하게 만듭니다. 이건 마치 인간이 토론과 협업을 통해 더 나은 결론에 도달하는 과정과 매우 닮아 있습니다.
예를 들어 Coral에서 정의한 ‘설득력(persuasiveness)’이나 ‘자기주장(assertiveness)’ 같은 사회적 지표는, 기존 LLM 평가에서 다뤄지지 않았던 요소입니다. 단순히 얼마나 많이 맞췄냐가 아니라, 문제 해결 과정에서 얼마나 적극적으로 의견을 제시하고, 상대를 설득하여 올바른 방향으로 이끌었는지를 정량적으로 측정한 것입니다.
놀랍게도 Coral로 훈련된 모델들은 협업 중에 무조건 상대의 의견을 따르기보다는, 잘못된 방향일 때는 ‘이건 아닌 것 같다’고 반박하고, 정답을 향해 스스로의 사고를 정교화하는 모습을 보여주었습니다. 특히 기존 LLM이 보였던 지나친 공손함(over-politeness)과 동조 성향이 Coral 학습 이후에는 점차 줄어든다는 점도 인상적입니다.
결국, GPT-4보다 높은 점수를 받은 것은 단순히 학습량이나 파라미터 크기 때문이 아니라, ‘함께 대화하고 생각하는 방식’ 자체가 근본적으로 달랐기 때문입니다. 이는 향후 인간-AI 협업 시대를 준비하는 데 있어, Coral과 같은 방식의 훈련이 중요한 전환점이 될 수 있음을 시사합니다.
8. 협업형 AI의 미래: 인간과 AI가 진짜 함께 일하는 날까지
Coral 프로젝트는 단지 새로운 훈련 기법을 제안한 것이 아닙니다. 이는 AI가 혼자서 똑똑해지는 시대에서, ‘같이’ 똑똑해지는 시대로 전환되고 있음을 보여주는 신호입니다. 특히 이 연구는 단순히 AI끼리의 협업에 머물지 않고, 향후 인간과 AI가 대등한 파트너로서 협력하는 구조를 그려내는 데 있어 매우 중요한 기초를 제공합니다.
오늘날 많은 AI는 여전히 ‘질문 → 답변’의 단방향 구조에 갇혀 있습니다. 사용자가 어떤 질문을 던지면, 그에 대해 가장 그럴듯한 한 가지 답변을 내놓는 식이죠. 하지만 실제 인간 협업은 그렇지 않습니다. 서로의 관점을 공유하고, 반박하고, 오해를 풀고, 종국에는 ‘합의’에 도달하는 복잡한 과정입니다.
Coral은 이런 점에서 획기적입니다. AI가 스스로 대화하며 배우고, 틀린 길로 가는 상대를 설득하거나, 자기주장을 펼치며 더 나은 결론을 찾아가는 과정은 진정한 협업의 시작이라 할 수 있습니다. 이는 단지 성능 향상을 위한 트릭이 아니라, AI에게 사회적 지능(social intelligence)을 부여하는 시도에 가깝습니다.
앞으로 AI는 단순한 도구가 아닌, 함께 문제를 해결하는 동료로 발전하게 될 것입니다. 교육, 연구, 개발, 상담, 기획 등 다양한 분야에서 인간과 AI가 ‘대화’를 통해 협업하는 방식은 점점 보편화될 것입니다. Coral은 그 미래를 위한 첫 번째 실험이자, 가장 인상적인 성과를 보여준 프로젝트라 할 수 있습니다.
Meta는 현재 Coral의 전체 프레임워크(Coral + Matrix)를 오픈소스로 공개하여, 더 많은 연구자들이 협업형 AI를 실험하고 발전시킬 수 있도록 지원하고 있습니다. 앞으로 Coral을 기반으로 한 다양한 파생 프로젝트가 등장할 것이며, 이는 협업형 AI의 저변을 더욱 넓혀줄 것입니다.
우리가 기대하는 AI는 더 이상 ‘혼자서 모든 걸 잘하는 AI’가 아닙니다. 진짜 미래는, 함께 일하며 더 나은 결론을 도출해내는 AI, 그리고 그런 AI와 함께 일하는 인간의 모습일 것입니다.
결론
Meta의 Coral 프로젝트는 AI가 단독으로 문제를 푸는 단계를 넘어, ‘서로 대화하며 배우는’ 협업형 지능의 가능성을 제시했습니다. 기존 LLM의 한계였던 과도한 동조, 낮은 설득력, 부족한 자기주장을 보완하며, AI가 함께 더 나은 답을 찾아가는 모습을 보여준 것이죠.
Coral을 통해 훈련된 모델들은 실제로 GPT-4를 능가하는 정확도를 기록하며, 협업 기반 학습의 효과를 입증했습니다. 이는 단순한 성능 개선을 넘어서, AI가 인간과 진짜로 협력할 수 있는 기반을 마련했다는 의미입니다.
이제 우리는 ‘AI가 얼마나 똑똑한가’보다는 ‘AI와 어떻게 함께 일할 수 있을까’를 고민해야 할 시점에 와 있습니다. Coral은 그 질문에 가장 흥미로운 첫 답을 제시한 셈입니다.
↓ Coral과 같은 AI 패러다임을 직접 활용하고 비즈니스하는 법 보러가기 ↓








