Last updated on 8월 21st, 2025 at 06:40 오후
본 포스팅은 인공지능 분야 전문 유튜버 ‘sudoremove’님의 콘텐츠를 바탕으로 재구성하였습니다. 일부 표현과 설명은 블로그 형식에 맞게 편집 · 가공하였습니다.
RTX 5090으로 GPT-OSS-20B 로컬 구동하기
2025년 8월 5일 자로 오픈 소스로 공개된 GPT-OSS-20B를 LM 스튜디오에서 확인해보겠습니다.
윈도우 버전으로도 쉽게 다운로드할 수 있습니다.
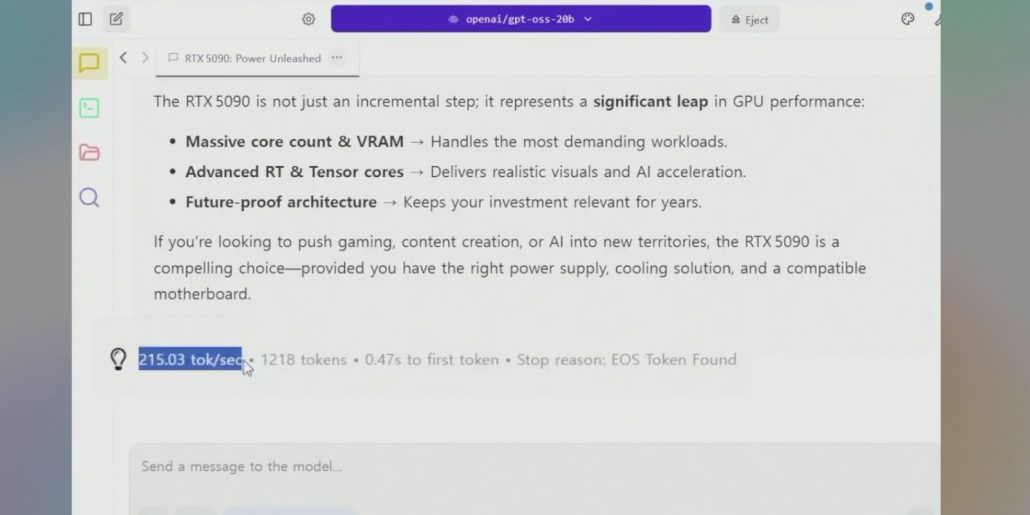
“RTX 5090 GPU 그래픽 카드에 대해서 장점을 잘 설명해봐” 채팅창에 물어봅니다.
*출처: ‘sudoremove’ 유튜브 영상 캡처
확인해 보고 싶었던 결과는 바로 이것입니다.
215.03 tok/sec
생성 속도가 “휘리릭~” 이 정도 속도로 나온다는 점입니다.
그다음 모델 설정에서 Context length를 조절해 좀 더 길게 답변을 받을 수 있도록 조정해 보았습니다. Reasoning Effort는 High로 설정해 오랫동안 생각하고 답변을 받을 수 있도록 하였습니다.

*출처: ‘sudoremove’ 유튜브 영상 캡처
이번에는 210.58 tok/sec · 2,190 tokens · 0.26s가 나왔습니다.
우리가 눈으로 읽는 것보다 빠르게 결과를 도출했습니다.

*출처: ‘sudoremove’ 유튜브 영상 캡처
M4 Pro Mac mini vs RTX 5090이 탑재된 데스크톱
이 결과가 얼마나 빠른 것인지 하나 더 비교해 보겠습니다.
M4 Pro Mac mini에서는 21.09 tok/sec가 나왔습니다. 10배 차이가 나죠.
💡 왜 차이가 나는 걸까요?
GPT-OSS-20B이면 메모리가 얼마나 커야 할까요?
요즘 대부분의 모델이 BF16 기준으로 잡습니다. 계산해 보면 최소 40GB가 필요합니다.
위와 같은 모델을 로컬 환경에서 구동하려면
그래픽 카드 VRAM이 최소 16GB가 필요합니다. RTX 5090의 경우 32GB이기 때문에 여유가 있습니다.
RTX 5090의 넉넉한 VRAM으로 튜닝도 가능합니다.
GPT-OSS 파인튜닝 로컬에서 실행하기
unsloth라는 프레임워크에서 제공하는 예제 코드를 사용하였습니다. 예제 코드는 OpenAI가 GPT-OSS를 공개한 날 동시에 COOKBOOK을 공개했으며, 해당 예제 코드의 unsloth 버전입니다. 효율적으로 튜닝하기 위해 LoRA라는 기법을 사용해 튜닝을 진행해 보겠습니다.
GPT-OSS에는 Reasoning Effort가 있습니다.
생각을 얼마나 오랫동안 고민하고 대답하느냐에 따라 답변 품질이 달라집니다.
프롬프트를 살펴보면 생각을 영어로 하는데, 허깅페이스(Hugging Face)에 있는 Multilingual-Thinking 데이터를 활용해 생각하는 과정을 다른 언어로 바꿔 보겠습니다.

*출처: ‘sudoremove’ 유튜브 영상 캡처
학습을 시켜 보겠습니다.
테스트를 위해 batch size는 1로 설정했습니다. 메모리를 확인해 보니 32GB 중 15GB를 사용하고 있네요. 학습 후 피크 메모리를 확인해 보겠습니다. 전체 20B 중 약 4M, 즉 0.2%만 학습시키려고 합니다.
일부만 학습시켜도 생각 언어를 바꾸는 능력은 구현할 수 있습니다.

*출처: ‘sudoremove’ 유튜브 영상 캡처
실제로 어느 정도 GPU가 있어야 가능한지를 확인해 보니 12분 정도 소요됐고, 피크 메모리는 23GB를 사용했습니다. 24GB의 RTX 4090으로는 겨우 구동 가능한 수준입니다. RTX 5090에서는 좀 더 빠르게 돌아가겠죠?

*출처: ‘sudoremove’ 유튜브 영상 캡처
RTX 5090 그래픽 카드가 있으면 로컬에서도 구동이 가능합니다. GPU를 빌려 쓰지 않아도 여러 가지 실험을 해 볼 수 있습니다. (*단, RTX 5090 그래픽 카드 외의 컴퓨터 하드웨어 사양에 따라 다릅니다.)
Comfy UI로 로컬에서 이미지 생성하기
워크플로 템플릿 중 Qwen-image를 사용해 보겠습니다.
입력한 프롬프트를 Diffusion Transformer에 함께 넣어 줍니다. 이미지가 생성되었습니다. 랜덤 시드 값을 바꿔 보겠습니다. 한자들이 생각보다 깔끔하게 잘 나왔네요.

*출처: ‘sudoremove’ 유튜브 영상 캡처
이유는 Qwen-image 모델이 complex text rendering에 특화돼 있기 때문입니다.
참고로, 아직 한국어는 제대로 된 이미지 생성이 어려웠습니다.

*출처: ‘sudoremove’ 유튜브 영상 캡처
GPU Utilization이 올라가는 것을 볼 수 있습니다.
약 21GB 정도로 측정되는데, RTX 4090 24GB로도 구동할 수 있습니다.
이번에는 Flux Krea Dev를 사용해 보겠습니다. 이 모델도 구조는 비슷합니다.
실행해 보니 사실적인 이미지가 잘 구현되었습니다. 이 모델의 Key Features에는 aesthetic photography가 포함되어 있으며, 사실적인 이미지를 만들어 내는 데 초점을 맞춘 모델입니다.

*출처: ‘sudoremove’ 유튜브 영상 캡처
위에서 Qwen-image로 실행해 보았던 홍콩 스타일의 이미지를 구현하기 위한 프롬프트를 Flux Krea Dev에서도 실행해 보겠습니다.

*출처: ‘sudoremove’ 유튜브 영상 캡처
글자가 제대로 표현되지 않고 깨진 부분이 여러 군데 있습니다.
원래 Diffusion 모델이 글자를 잘 구현하지는 못하는데, 생성 원리가 달라서 그렇습니다.
Comfy UI로 로컬에서 비디오 생성하기
이번에는 영상을 생성해 보겠습니다. Wan 2.2 5B 모델을 사용했습니다.
GPU를 확인해 보니 전용 GPU 메모리는 약 24GB를 사용하고 있고, GPU를 거의 100% 활용하고 있습니다. GPU 온도도 거의 70도까지 올라가네요.

*출처: ‘sudoremove’ 유튜브 영상 캡처
자, 영상이 만들어졌습니다. 일부 이상한 부분이 아쉽지만, 5B 모델로 만들 수 있는 최선인 것 같습니다.

*출처: ‘sudoremove’ 유튜브 영상 캡처
소비자용 그래픽 카드 중에서는 초고사양 모델인 RTX 5090이기 때문에 구현할 수 있는 것입니다. 비교해 보면 Qwen-image 같은 경우 GPU 소모량이 Flux Krea Dev 모델보다 크기 때문에 RTX 5090이 아니면 구현할 수 없겠죠? Wan 5B 모델도 약 24GB를 사용하기 때문에 RTX 5090으로는 구현할 수 있지만, 그 이하 메모리로는 구현이 어려울 것으로 보입니다.
RTX 5090 그래픽 카드를 사용해 여러 가지 AI 모델을 실험해 보며 로컬 구동을 진행해 보았습니다. 더욱 자세한 내용이 궁금하신 분들은 ‘sudoremove’ 유튜브 영상을 확인해 보세요.
✨RTX 5090 그래픽카드 이런 분들께 강력 추천 합니다✨
✔ 생성형 AI, LLM, 딥러닝 프로젝트를 직접 실행해보고 싶은 분
✔ 무거운 3D 툴, 고해상도 편집, 실시간 렌더링 환경이 필요한 분
✔ 성능 한계를 느끼고 있는 기존 시스템을 교체하고 싶은 분
✔ 초고사양 게임을 끊김 없이 몰입형 그래픽으로 즐기고 싶은 분
8월 22일까지 구매할 수 있는 RTX 5090 + 강의 4개 패키지 특가를 소개해 드립니다.
그래픽 카드 구매를 계획하고 있는 분들께 합리적인 가격에 구매할 수 있는 좋은 기회입니다.