Last updated on 3월 6th, 2025 at 01:49 오후
MS Office를 못 쓰는 지원자를 회사에서 뽑지 않듯,
앞으로는 데이터 역량이 MS Office의 자리를 대체할 것이다.
예전에는 데이터로 무언가 하고 싶어도, 활용할 수 있는 데이터가 존재하지 않았다. 하지만 오늘날에는 생활의 대부분이 온라인화 되면서, 사람들의 일상이 디지털로 기록되고 데이터로 남겨진다. 이렇게 쌓이는 데이터 안에서 숨겨진 기회를 찾아 시장을 점유하는 비즈니스들도 어렵지 않게 찾아볼 수 있게 되었다.

일례로, 옛날에는 광고를 한다고 하면 몇 천 만 원 단위의 예산이 드는 TV 광고 같은 전통매체 외에는 선택지가 별로 없었다. 반면 지금은 네이버나 카카오 플랫폼에서 단돈 3만 원만 있어도 광고를 집행할 수 있게 되었다. 한 줌의 데이터와 소액의 돈만 있어도 원하는 광고를 집행할 수 있는 마이크로(Micro)의 시대가 도래하면서, 주도권이 개인에게 넘어온 것이다.
데이터 사이언티스트는 무슨 일을 하는가?
이렇게 모인 데이터에서 통계나 머신러닝 기술을 활용하여 비즈니스 기회를 찾고, 이를 현실화 하는 사람이 바로 데이터 사이언티스트(Data Scientist)이다.

데이터 사이언스에서 ‘사이언스’는 단어 그대로 ‘과학(Science)’이다. 과학은 가설을 세우고, 실험을 설계한 뒤 수행하고, 그 결과를 분석하는 과정을 계속해서 반복한다. 그러므로 데이터 사이언티스트는 실험을 통해 문제를 개선하고 그 개선 결과를 분석하여 다음 실험과 액션을 도출하는 사람인 것이다.
데이터 사이언스와 데이터 분석의 차이는 무엇일까?
최근에는 데이터에 대한 대중적 관심이 높아지면서, 데이터 분석과 데이터 사이언스를 혼용하는 일이 잦아졌다. 하지만 데이터 사이언티스트의 일과 데이터 분석가의 일은 엄연히 다르다. 실험을 설계하고 수행하여 문제를 개선하는 과정이 없다면, 그 일은 데이터 분석에 지나지 않기 때문이다. 이 점이 데이터 분석가와 사이언티스트의 가장 큰 차이이다.

따라서 기업의 데이터 팀은 실험을 설계하고 개선을 위한 액션을 수행하고 있어야 한다. 실제로 데이터 사이언스 분야의 업무는 개별 스킬로 완성되지 않는다. 특히, 데이터 사이언티스트의 일에서 ‘분석’은 굉장히 일부이다. 중요한 건, 우리가 당장 해결해야 하는 문제를 찾는 것이다. 동시에 비즈니스의 본질을 이해하는 단계가 선행되어야 한다.
기업에서는 어떤 데이터 인력을 선호할까?
면접관으로 회사에서 신입과 경력직 가리지 않고 많은 데이터 인력을 뽑아보았다. 일단 최근 몇 년 사이 느끼는 것은 면접을 보러 오는 분들의 수준이 예전보다 훨씬 높아졌다는 점이다. 특히, 캐글과 머신러닝과 관련된 질문에는 대답의 수준이 높아서, 현업에서 일하는 실무자보다도 아는 게 더 많은 때도 있다.

반면, 채용하고 나서 실제로 업무를 진행시켜 보면 난감해진다. 사실 데이터 업무에서 필요한 역량은 단순한 분석을 넘어선다. 데이터를 존재하게 하는 과정, 데이터를 가공하고 전처리하는 과정, 또는 기초적인 백엔드 지식이나 커뮤니케이션 역량도 필요하다. 이론도 많이 알고, 해본 것도 다양하여 일을 잘 할 수 있을 것이라 판단하고 채용했는데 분석 외의 다른 역량에 대한 지식이나 경험치는 전무한 경우가 꽤 많다.
이 경우, 회사 입장에서는 일종의 부상병을 데리고 일하는 것과 같다. 다른 사람과 ‘페어(Pair)’로 일하지 않고서야, 혼자서는 1인이 해야 하는 기본 업무를 처리하지 못하는 것이다.
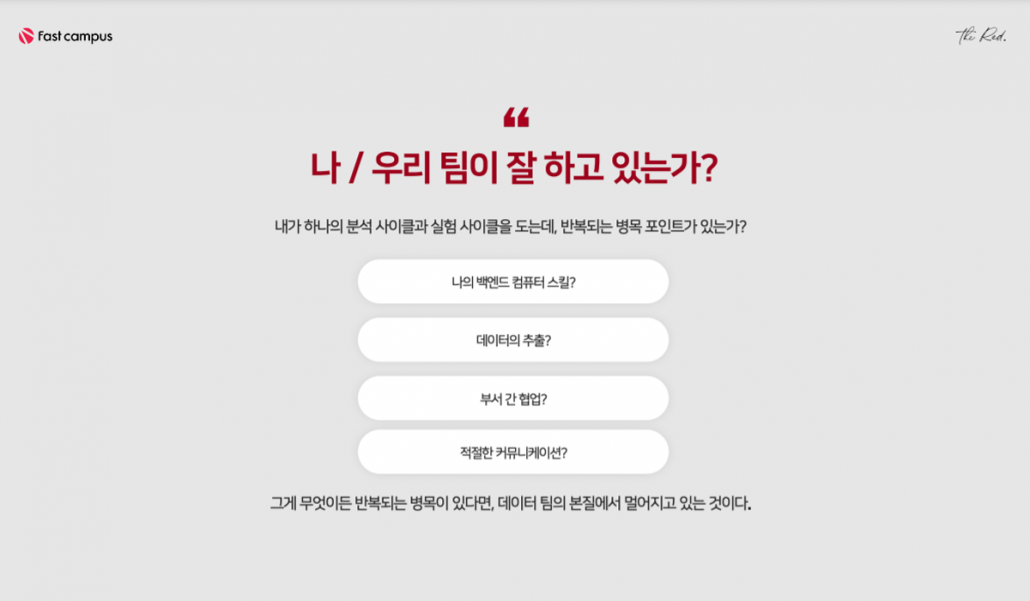
사실 회사에서 주로 쓰는 분석 기법은 대부분 정해져 있다. 지원자들의 분석 역량이 이전보다 상향 평준화 되었기도 하고, 기업에서 사용하는 분석 기법은 입사 후 일정 기간 내에 전수 가능하다.
결국, 최근에는 분석 역량에 대한 확인 뿐만 아니라, 이전 단계에서 필요한 전처리 경험이나 백엔드 지식에 대한 질문을 많이 하기 시작했다. 여기서 좋은 대답을 한 지원자들이 현업에서도 높은 업무 역량을 보여주고 있다.
현실의 머신 러닝과 딥 러닝은 어떻게 다를까?
회사에서 만나는 데이터는 실제로 취업 전에 머릿속으로 상상하던 그것과 많이 다르다. 일단 회사의 데이터는 다음과 같은 특징을 가진다.
관련 글 더보기 : 머신러닝 딥러닝, 아직도 헷갈리는 사람을 위한 완벽 개념 정리
- 대부분 DB 형태로 저장되며, 테이블로 정리되어 있다.
- 생각보다 양이 많지 않아, 소용량에서 중용량 정도로 봐야 한다.
- 편향된(Imbalanced) 데이터가 많아서, 머신러닝 학습을 위한 사전 작업이 필요하다.
- 많은 쪽을 적은 쪽에 맞추는 Subsampling 과정으로 학습 가능한 데이터 수는 더 줄어든다.
- 빅데이터 시대임에도, 실제 머신러닝 학습을 위한 데이터는 늘 모자란 편이다.
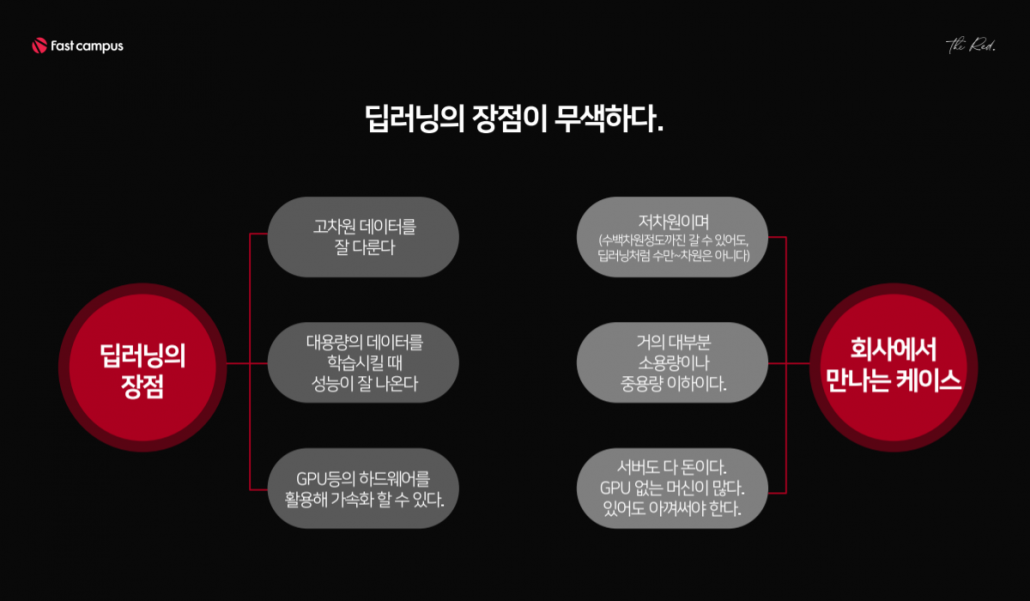
그러다 보니, 고차원의 대용량 데이터를 다루는데 최적인 딥러닝의 장점이 회사 데이터 앞에서는 무색해진다. 회사에서 다루는 데이터의 케이스는 대부분 저차원에, 소용량 또는 중용량이기 때문이다. 동시에, 서버를 돌리는 것도 다 돈이라 GPU가 없는 머신도 흔하다.
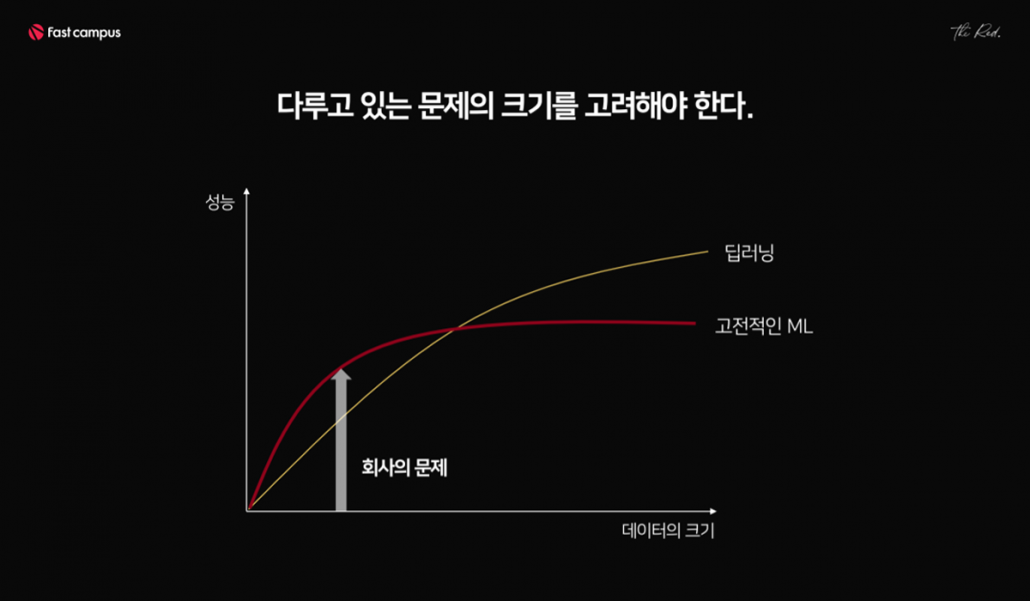
이러한 이유로 현업에서는 고전적 머신러닝을 딥러닝보다 선호하며, 실제로도 많이 활용한다. 고차원의 문제를 해결해야 하는 상황이라면 딥러닝 기법을 활용했을 때 큰 성장을 기대할 수 있을 것이다. 하지만 테이블로 정리된 회사 DB로 학습하는 것이라면, 고전 머신러닝 기법도 충분히 효과적이다.
딥러닝에 대해 체계적으로 배우고 싶다면 아래 강의를 추천한다. 탄탄한 커리큘럼과 실습 중심으로 비전공자도 쉽게 이해할 수 있다. 게다가 무료로 들을 수 있어 비용 걱정도 없다.